
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.

Многие начинающие программисты, когда сталкиваются с SQL, не знают о такой возможности как группировка данных с помощью оператора GROUP BY, хотя эта возможность требуется достаточно часто на практике, в связи с этим наш сегодняшний урок, как обычно с примерами, посвящен именно тому, чтобы Вам было проще и легче научиться использовать данный оператор, так как Вы с этим обязательно столкнетесь. Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
И для вступления небольшая теория.
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
CREATE TABLE [dbo].[test_table](
[id] [int] NULL,
[name] [varchar](50) NULL,
[summa] [money] NULL,
[priz] [int] NULL
) ON [PRIMARY]
GO
Я ее заполнил следующими данными:
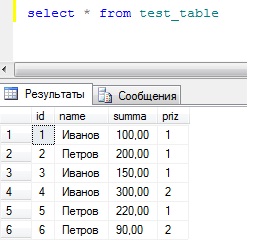
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
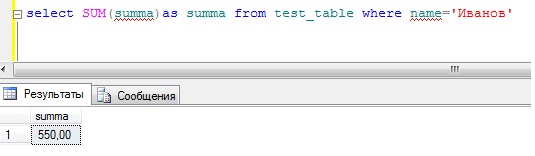
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
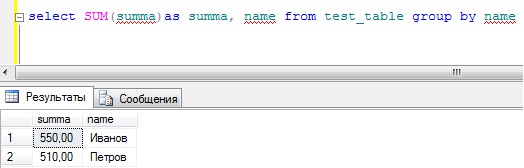
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник]
FROM test_table
GROUP BY name
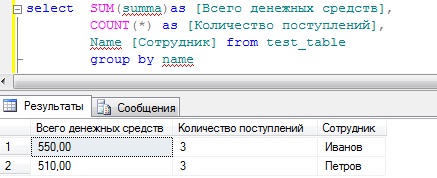
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник] ,
Priz [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
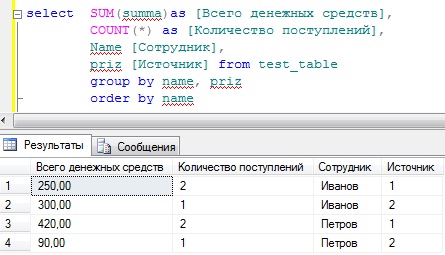
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств],
COUNT(*) AS [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
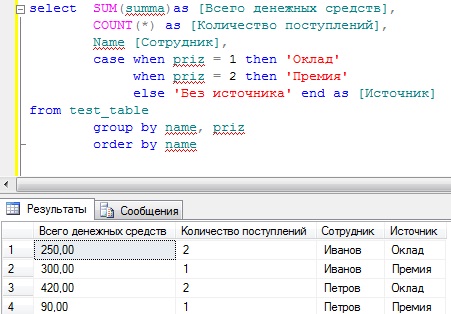
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
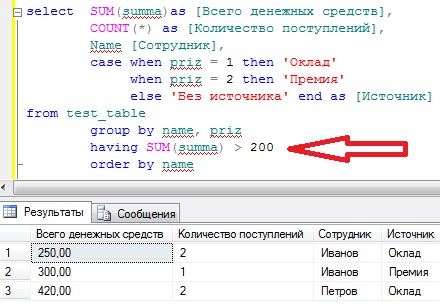
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.







огромное спасибо! самая понятная статья в Рунете на эту тему, на мой взгляд.