
Всем привет! Сейчас мы рассмотрим возможность Microsoft SQL Server получать из XML данных привычные для нас табличные данные, иными словами, мы поговорим о том, как извлекать данные из XML документа. В языке T-SQL это реализуется с помощью специальной конструкции OPENXML.

Ранее, в материале «Создание XML данных с помощью конструкции FOR XML», мы рассмотрели возможность SQL Server формировать XML документы на языке T-SQL, например, для того чтобы передавать их какому-нибудь клиентскому приложению. Сегодня мы научимся обрабатывать XML данные, которые поступают к нам, например, все от того же клиентского приложения. Если Вам необходимо просто сохранить XML документ, то, конечно же, извлекать из него данные необязательно, Вам достаточно сохранить их в таблице в столбце с типом данных XML. Но если Вам нужна информация, которая есть в этом XML документе, например, для ее сохранения в определённой табличной структуре, то Вам придётся обработать этот XML документ и извлечь из него соответствующие данные.
В Microsoft SQL Server извлечь данные из XML документа можно с помощью функции OPENXML.
OPENXML в Microsoft SQL Server
OPENXML – это специальная функция, которая извлекает данные из XML документа. Другими словами, она может на входе получить XML данные, а на выходе дать нам результирующий набор строк, как будто это результат запроса к обычным таблицам или представлениям. Эти данные мы, соответственно, можем сохранить или сразу провести какой-то анализ.
OPENXML — это не просто табличная функция, как было уже отмечено, это целая конструкция, так как чтобы использовать функцию, XML документ предварительно необходимо подготовить. А делается это с помощью системной хранимой процедуры sp_xml_preparedocument, которая проводит синтаксический анализ XML данных и возвращает дескриптор XML документа, который мы и передаем в функцию OPENXML для извлечения данных.
После того как мы извлечем данные, дескриптор XML документа необходимо удалить системной процедурой sp_xml_removedocument, для того чтобы освободить память. Можно этого и не делать, тогда в этом случае дескриптор будет существовать до конца сеанса (но чтобы избежать проблем с недостатком памяти, рекомендовано вручную удалять дескриптор, т.е. использовать процедуру).
Функция OPENXML имеет несколько параметров:
- Первый – дескриптор XML документа;
- Второй – шаблон на языке XPath, используемый для идентификации узлов, которые будут обрабатываться как строки;
- Третий – тип сопоставления между XML данными и реляционными, например, 0 – используется атрибутивная модель сопоставления, это значение по умолчанию, 1 — использовать атрибутивную модель сопоставления, 2 — использовать сопоставление с использованием элементов, 8 — используемые данные не должны копироваться в свойство переполнения @mp:xmltext.
После функции, с помощью ключевого слова WITH, указывается формат набора выходных строк, т.е. мы перечисляем столбцы и их тип данных.
Примеры работы функции OPENXML в T-SQL
Для того чтобы посмотреть, как работает данная функция, давайте сначала сформируем XML документ, а затем извлечем из него данные в табличном виде. Для этого нам нужны данные, давайте их добавим.
Все примеры будут выполнены в Microsoft SQL Server 2016 Express.
Примечание! Начинающим рекомендую ознакомиться с материалом «Справочник по Transact-SQL».
Исходные данные для примера
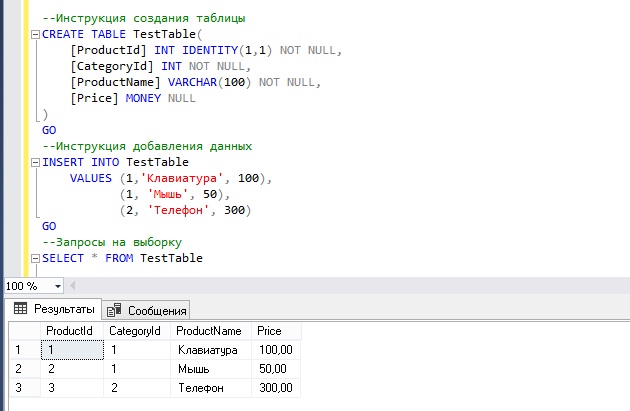
--Инструкция создания таблицы
CREATE TABLE TestTable(
[ProductId] INT IDENTITY(1,1) NOT NULL,
[CategoryId] INT NOT NULL,
[ProductName] VARCHAR(100) NOT NULL,
[Price] MONEY NULL
)
GO
--Инструкция добавления данных
INSERT INTO TestTable
VALUES (1,'Клавиатура', 100),
(1, 'Мышь', 50),
(2, 'Телефон', 300)
GO
--Запросы на выборку
SELECT * FROM TestTable
Извлечение данных из XML документа функцией OPENXML
Чтобы сформировать XML документ, мы используем конструкцию FOR XML. Затем с помощью функции OPENXML мы извлечем данные из полученного документа. Код в примере ниже я прокомментировал.
--Объявляем переменные
DECLARE @XML_Doc XML;
DECLARE @XML_Doc_Handle INT;
--Формируем XML документ
SET @XML_Doc = (
SELECT ProductId AS "@Id", ProductName, Price
FROM TestTable
ORDER BY ProductId
FOR XML PATH ('Product'), TYPE, ROOT ('Products')
);
--Подготавливаем XML документ
EXEC sp_xml_preparedocument @XML_Doc_Handle OUTPUT, @XML_Doc;
--Извлекаем данные из XML документа
SELECT *
FROM OPENXML (@XML_Doc_Handle, '/Products/Product', 2)
WITH (
ProductId INT '@Id',
ProductName VARCHAR(100),
Price MONEY
);
--Удаляем дескриптор XML документа
EXEC sp_xml_removedocument @XML_Doc_Handle;
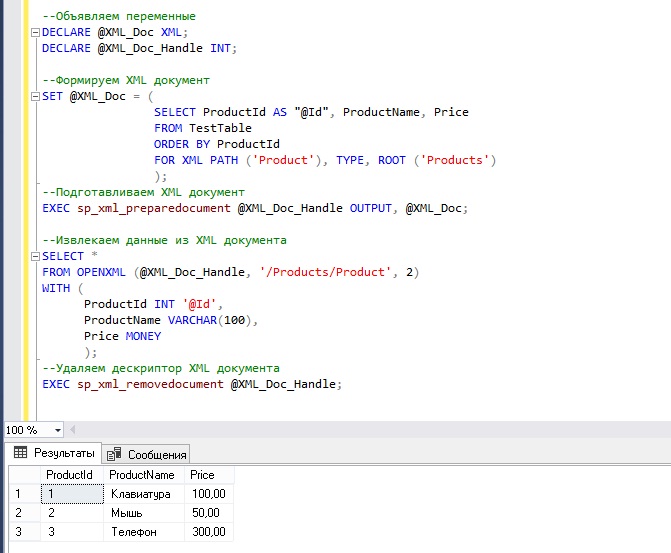
В данном примере в переменной @XML_Doc мы сохранили XML документ, потом мы данную переменную передали на анализ системной процедуре sp_xml_preparedocument, которая вернула нам дескриптор XML документа в переменной @XML_Doc_Handle (если XML документ составлен синтаксически неправильно, выйдет ошибка).
В функцию OPENXML мы передаем переменную с дескриптором, указываем, какой элемент будет являться строкой, в нашем случае каждый элемент Product это строка, а также уточняем, какой метод сопоставления использовать, в нашем случае с использованием элементов.
В секции WITH мы перечислили название и тип итоговых столбцов, для ProductId мы указали дополнительный аргумент ‘@Id’ — это говорит о том, что данный столбец в XML документе является атрибутом Id.
После того как XML документ мы обработали, удаляем его дескриптор процедурой sp_xml_removedocument, передав в нее, соответственно, переменную с дескриптором.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
На этом все, пока!







Привет!
Отличная статья, очень сильно помогла понять принцип действия openxml.
Остался единственный неясный момент по методам сопоставляния: как определить в каком случае какой метод лучше использовать?