
В данном материале будут рассмотрены такие объекты базы данных Microsoft SQL Server как индексы, Вы узнаете, что такое индексы, какие типы индексов бывают, как их создавать, оптимизировать и удалять.
Что такое индексы в базе данных?

Индекс — это объект базы данных, который представляет собой структуру данных, состоящую из ключей, построенных на основе одного или нескольких столбцов таблицы или представления, и указателей, которые сопоставляются с местом хранения заданных данных. Индексы предназначены для более быстрого получения строк из таблицы, другими словами, индексы обеспечивают быстрый поиск данных в таблице, что значительно повышает производительность запросов и приложений. Индексы также могут быть использованы и для обеспечения уникальности строк таблицы, гарантируя тем самым целостность данных.
Типы индексов в Microsoft SQL Server
В Microsoft SQL Server существуют следующие типы индексов:
- Кластеризованный (Clustered) – это индекс, который хранит данные таблицы в отсортированном, по значению ключа индекса, виде. У таблицы может быть только один кластеризованный индекс, так как данные могут быть отсортированы только в одном порядке. По возможности каждая таблица должна иметь кластеризованный индекс, если у таблицы нет кластеризованного индекса, такая таблица называется «кучей». Кластеризованный индекс создается автоматически при создании ограничений PRIMARY KEY (первичный ключ) и UNIQUE, если до этого кластеризованный индекс для таблицы еще не был определен. В случае создания кластеризованного индекса для таблицы (кучи), в которой есть некластеризованные индексы, то после создания все их необходимо перестроить.
- Некластеризованный (Nonclustered) – это индекс, который содержит значение ключа и указатель на строку данных, содержащую значение этого ключа. У таблицы может быть несколько некластеризованных индексов. Создаваться некластеризованные индексы могут как на таблицах с кластеризованным индексом, так и без него. Именно этот тип индекса используется для повышения производительности часто используемых запросов, так как некластеризованные индексы обеспечивают быстрый поиск и доступ к данным по значениям ключа;
- Фильтруемый (Filtered) – это оптимизированный некластеризованный индекс, который использует предикат фильтра для индексирования части строк в таблице. Если хорошо спроектировать такой тип индекса, то он может повысить производительность запросов, а также снизить затраты на обслуживание и хранение индексов по сравнению с полнотабличными индексами;
- Уникальный (Unique) – это индекс, который обеспечивает отсутствие повторяющихся (одинаковых) значений ключа индекса, гарантируя тем самым уникальность строк по данному ключу. Уникальными могут быть как кластеризованные, так и некластеризованные индексы. Если создавать уникальный индекс по нескольким столбцам, индекс гарантирует уникальность каждой комбинации значений в ключе. При создании ограничений PRIMARY KEY или UNIQUE SQL сервер автоматически создает уникальный индекс для ключевых столбцов. Уникальный индекс может быть создан только в том случае, если у таблицы на текущий момент отсутствуют дублирующие значения по ключевым столбцам;
- Колоночный (Columnstore) – это индекс, основанный на технологии хранения данных в виде столбцов. Данный тип индекса эффективно использовать для больших хранилищ данных, поскольку он может увеличить производительность запросов к хранилищу до 10 раз и также до 10 раз уменьшить размер данных, так как данные в Columnstore индексе сжимаются. Существуют как кластеризованные колоночные индексы, так и некластеризованные;
- Полнотекстовый (Full-text) – это специальный тип индекса, который обеспечивает эффективную поддержку сложных операций поиска слов в символьных строковых данных. Процесс создания и обслуживания полнотекстового индекса называется «заполнением». Существует такие типы заполнения как: полное заполнение и заполнение на основе отслеживания изменений. По умолчанию SQL сервер полностью заполняет новый полнотекстовый индекс сразу после его создания, но на это может потребоваться значительный объем ресурсов, в зависимости от размеров таблицы, поэтому есть возможность откладывать полное заполнение. Заполнение на основе отслеживания изменений используется для обслуживания полнотекстового индекса после его первоначального полного заполнения;
- Пространственный (Spatial) – это индекс, который обеспечивает возможность более эффективного использования конкретных операций на пространственных объектах в столбцах с типом данных geometry или geography. Данный тип индекса может быть создан только для пространственного столбца, также таблица, для которой определяется пространственный индекс, должна содержать первичный ключ (PRIMARY KEY);
- XML – это еще один специальный тип индекса, который предназначен для столбцов с типом данных XML. Благодаря XML-индексу повышается эффективность обработки запросов к XML столбцам. Существует два вида XML-индекса: первичные и вторичные. Первичный XML-индекс индексирует все теги, значения и пути, хранимые в XML столбце. Он может быть создан, только если у таблицы есть кластеризованный индекс по первичному ключу. Вторичный XML-индекс может быть создан, только если у таблицы есть первичный XML-индекс и используется он для повышения производительности запросов по определенному типу обращения к XML-столбцу, в связи с этим существует несколько типов вторичных индексов: PATH, VALUE и PROPERTY;
- Также существуют специальные индексы для таблиц, оптимизированных для памяти (In-Memory OLTP) такие как: Хэш (Hash) индексы и некластеризованные индексы, оптимизированные для памяти, которые создаются для сканирования диапазона и упорядоченного сканирования.
Создание и удаление индексов в Microsoft SQL Server
Перед тем как приступать к созданию индекса его необходимо хорошо спроектировать, для того чтобы эффективно использовать этот индекс, так как плохо спроектированные индексы могут не увеличить производительность, а наоборот снизить ее. Например, большое количество индексов в таблице снижает производительность инструкций INSERT, UPDATE, DELETE и MERGE, потому что при изменении данных в таблице все индексы должны быть изменены соответствующим образом. Общие рекомендации по проектированию индексов мы с Вами рассмотрим в отдельном материале, а сейчас давайте переходить непосредственно к рассмотрению процесса создания и удаления индексов.
Примечание! В качестве SQL сервера у меня выступает версия Microsoft SQL Server 2016 Express.
Создание индексов
Для создания индексов в Microsoft SQL Server существует два способа: первый – это с помощью графического интерфейса среды SQL Server Management Studio (SSMS), и второй – это с помощью языка Transact-SQL, мы с Вами разберем оба способа.
Исходные данные для примеров
Давайте представим, что у нас есть таблица с товарами под названием TestTable, в которой есть три столбца:
- ProductId – идентификатор товара;
- ProductName – наименование товара;
- CategoryID – категория товара.
CREATE TABLE TestTable(
ProductId INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(50) NOT NULL,
CategoryID INT NULL,
) ON [PRIMARY]
Пример создания кластеризованного индекса
Как я уже говорил, кластеризованный индекс создается автоматически, если мы, например, при создании таблицы указываем конкретный столбец в качестве первичного ключа (PRIMARY KEY), но так как мы этого не сделали, давайте рассмотрим пример самостоятельного создания кластеризованного индекса.
Для создания кластеризованного индекса мы можем у таблицы указать первичный ключ, и тем самым кластеризованный индекс будет создан автоматически или мы можем создать кластеризованный индекс отдельно.
Для примера давайте просто создадим кластеризованный индекс, без создания первичного ключа. Сначала сделаем это с помощью Management Studio.
Открываем SSMS и в обозревателе объектов находим нужную таблицу и щелкаем правой кнопкой мыши по пункту «Индексы», выбираем «Создать индекс» и тип индекса, в нашем случае «Кластеризованный».
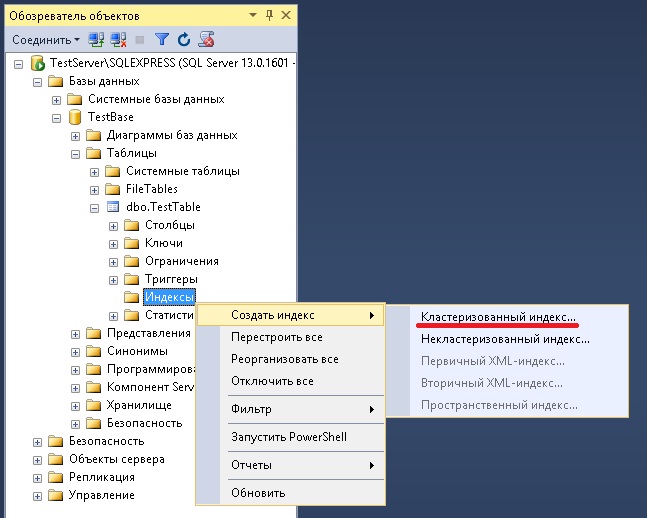
Откроется форма «Новый индекс», где нам необходимо указать имя нового индекса (оно должно быть уникальным в пределах таблицы), также указываем, будет ли этот индекс уникальным, если мы говорим об идентификаторе товара в таблице товаров, то, конечно же, он должен быть уникальным. Потом выбираем столбец (ключ индекса), на основе которого у нас будет создан кластеризованный индекс, т.е. будут отсортированы строки данных в таблице, с помощью кнопки «Добавить».
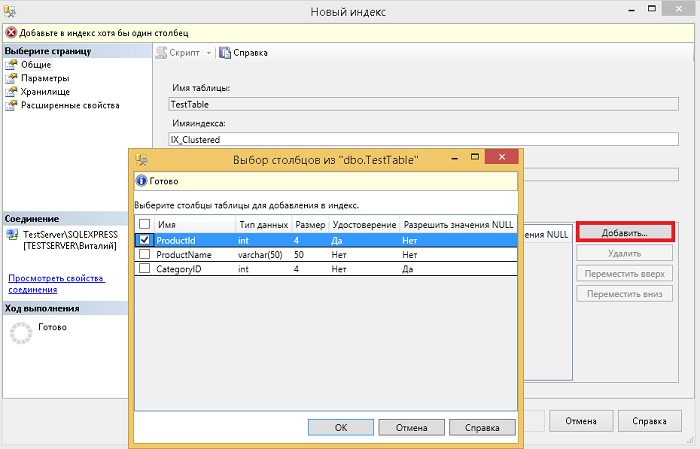
После ввода всех необходимых параметров жмем «ОК», в итоге будет создан кластеризованный индекс.
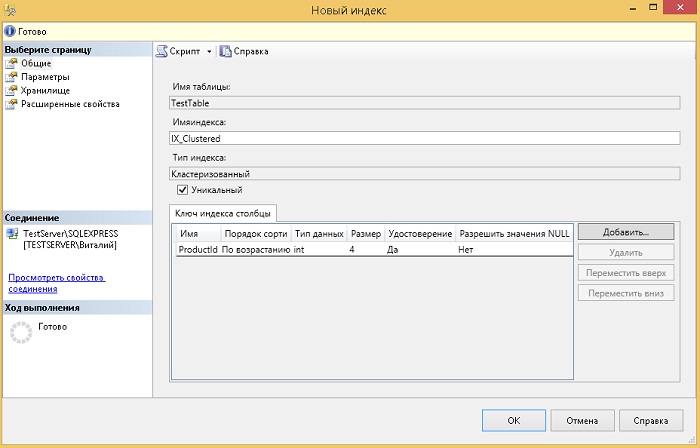
Точно также можно было бы создать кластеризованный индекс, используя инструкцию T-SQL CREATRE INDEX, например, вот так
CREATE UNIQUE CLUSTERED INDEX IX_Clustered ON TestTable
(
ProductId ASC
)
GO
Или, как мы уже говорили, можно было бы использовать и инструкцию создания первичного ключа, например
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED
(
ProductId ASC
)
GO
Пример создания некластеризованного индекса с включенными столбцами
Сейчас давайте рассмотрим пример создания некластеризованного индекса, при этом мы укажем столбцы, которые не будет являться ключевыми, но будут включаться в индекс. Это полезно в тех случаях, когда Вы создаете индекс для конкретного запроса, например, для того чтобы индекс полностью покрывал запрос, т.е. содержал все столбцы (это называется «Покрытием запроса»). Благодаря покрытию запроса повышается производительность, так как оптимизатор запросов может найти все значения столбцов в индексе, при этом не обращаясь к данным таблиц, что приводит к меньшему числу дисковых операций ввода-вывода. Но помните, что включение в индекс неключевых столбцов влечет за собой увеличение размера индекса, т.е. для хранения индекса потребуется больше места на диске, а также может повлечь и снижение производительности операций INSERT, UPDATE, DELETE и MERGE на базовой таблице.
Для того чтобы создать некластеризованный индекс с помощью графического интерфейса Management Studio, мы также находим нужную таблицу и пункт индексы, только в данном случае мы выбираем «Создать -> Некластеризованный индекс».
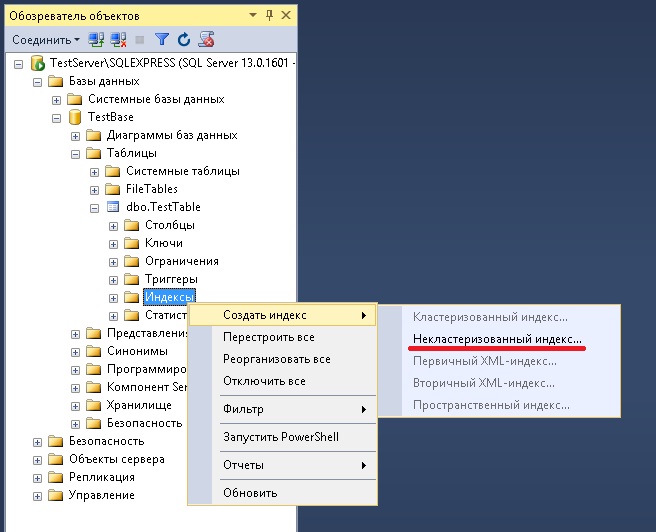
После открытия формы «Новый индекс» мы указываем название индекса, добавляем ключевой столбец или столбцы с помощью кнопки «Добавить», например, для нашего тестового случая давайте укажем CategoryID.
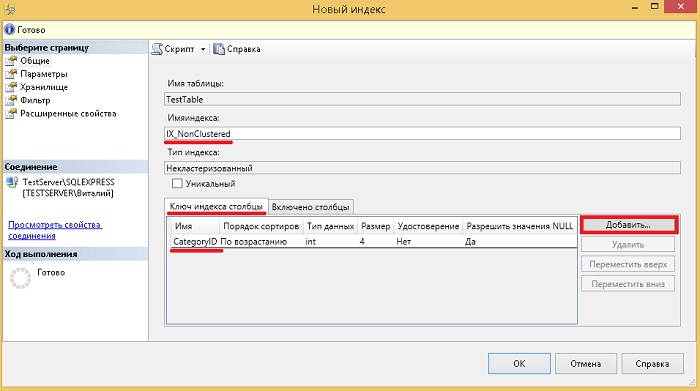
Далее переходим на вкладку «Включено столбцы» и с помощью кнопки «Добавить» добавляем столбцы, которые мы хотим включить в индекс, в нашем случае, например, ProductName.
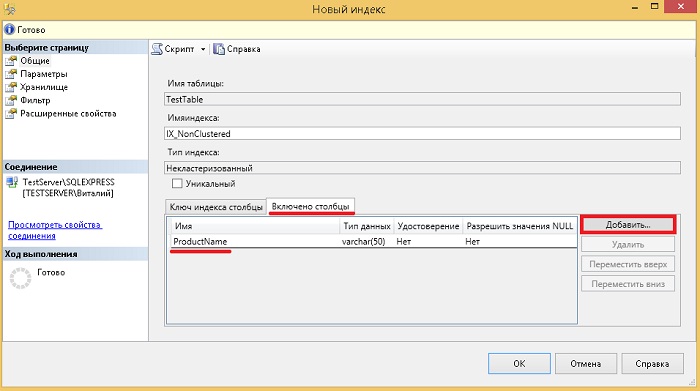
На Transact-SQL это будет выглядеть следующим образом.
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable
(
CategoryID ASC
)
INCLUDE (ProductName)
GO
Пример удаления индекса в Microsoft SQL Server
Для того чтобы удалить индекс можно щелкнуть правой кнопкой по нужному индексу и нажать «Удалить», затем подтвердить свое действия нажав «ОК».
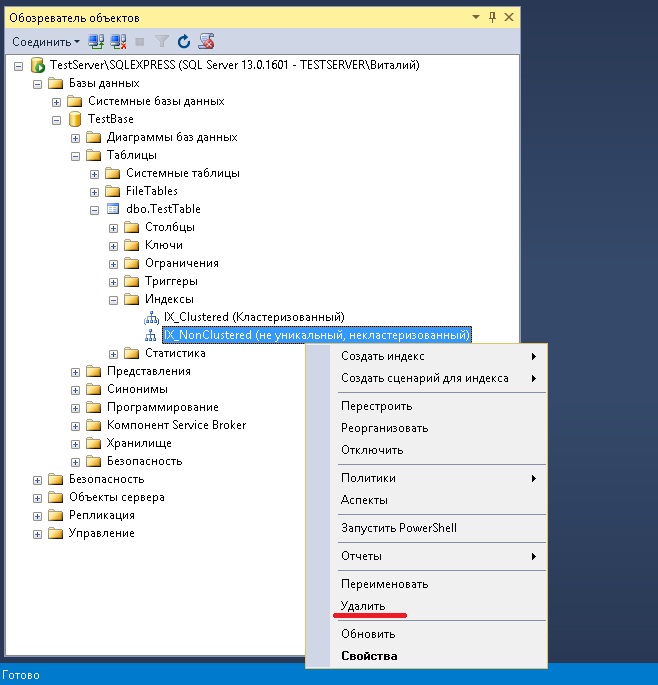
или также можно использовать инструкцию DROP INDEX, например
DROP INDEX IX_NonClustered ON TestTable
Следует отметить, что инструкция DROP INDEX неприменима к индексам, которые были созданы путем создания ограничений PRIMARY KEY и UNIQUE. В данном случае для удаления индекса нужно использовать инструкцию ALTER TABLE с предложением DROP CONSTRAINT.
Оптимизация индексов в Microsoft SQL Server
В результате выполнения операций обновления, добавления или удаления данных в таблицах SQL сервер автоматически вносит соответствующие изменения в индексы, но со временем все эти изменения могут вызвать фрагментацию данных в индексе, т.е. они окажутся разбросанными по базе данных. Фрагментация индексов влечет за собой снижение производительности запросов, поэтому периодически необходимо выполнять операции обслуживания индексов, а именно дефрагментацию, к таким можно отнести операции реорганизации и перестроения индексов.
В каких случаях использовать реорганизацию индекса, а в каких перестроение?
Чтобы ответить на этот вопрос сначала необходимо определить степень фрагментации индекса, так как в зависимости от фрагментации индекса тот или иной метод дефрагментации будет предпочтительней и эффективней. Для определения степени фрагментации индекса можно использовать системную табличную функцию sys.dm_db_index_physical_stats, которая возвращает подробные сведения о размере и фрагментации индексов. Например, используя следующий запрос, Вы можете узнать степень фрагментации индексов у всех таблиц в текущей базе данных.
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name AS IndexName,
T1.avg_fragmentation_in_percent AS Fragmentation
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1
LEFT JOIN sys.indexes AS T2 ON T1.object_id = T2.object_id AND T1.index_id = T2.index_id
В данном случае нас интересует столбец avg_fragmentation_in_percent, т.е. процентная доля логической фрагментации.
Так вот, Microsoft рекомендует:
- Если степень фрагментации менее 5%, то реорганизацию или перестроение индекса вообще не стоит запускать;
- Если степень фрагментации от 5 до 30%, то имеет смысл запустить реорганизацию индекса, так как данная операция использует минимальные системные ресурсы и не требует долговременных блокировок;
- Если степень фрагментации более 30%, то необходимо выполнять перестроение индекса, так как данная операция, при значительной фрагментации, дает больший эффект чем операция реорганизации индекса.
Лично я могу добавить следующее, если у Вас небольшая компания и база данных не требует максимальной отдачи в режиме 24 часа в сутки, т.е. она не суперактивная БД, то Вы можете смело периодически выполнять операцию перестроения индексов, при этом даже не определяя степень фрагментации.
Реорганизация индексов
Реорганизация индекса – это процесс дефрагментации индекса, который дефрагментирует конечный уровень кластеризованных и некластеризованных индексов по таблицам и представлениям, физически переупорядочивая страницы концевого уровня в соответствии с логическим порядком (слева направо) конечных узлов.
Для реорганизации индекса можно использовать как графический инструмент SSMS, так и инструкцию Transact-SQL.
Реорганизация индекса с помощью Management Studio
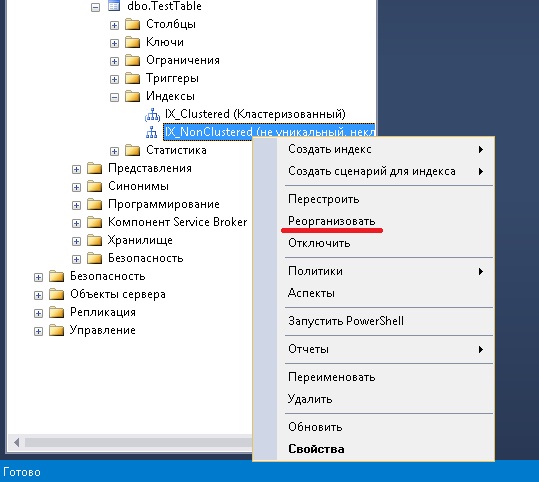
Реорганизация индекса с помощью Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Перестроение индексов
Перестроение индекса – это процесс, при котором происходит удаление старого индекса и создание нового, в результате чего фрагментация устраняется.
Для перестроения индексов можно использовать два способа.
Первый. Используя инструкцию ALTER INDEX с предложением REBUILD. Эта инструкция заменяет инструкцию DBCC DBREINDEX. Обычно для массового перестроения индексов используется именно этот способ.
Пример
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
И второй, используя инструкцию CREATE INDEX с предложением DROP_EXISTING. Можно использовать, например, для перестроения индекса с изменением его определения, т.е. добавления или удаления ключевых столбцов.
Пример
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable
(
CategoryID ASC
)
WITH(DROP_EXISTING = ON)
GO
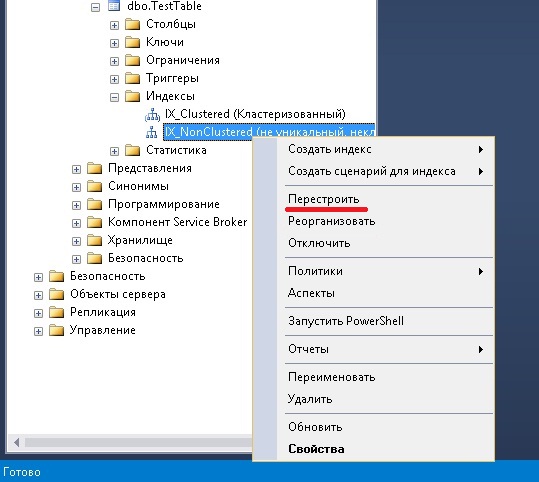
В Management Studio функционал для перестроения также доступен. Правой кнопкой по нужному индексу «Перестроить».
На этом материал по основам индексов в Microsoft SQL Server закончен, если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server, удачи!







Приглашаю всех желающих пройти мои онлайн-курсы по изучению языка T-SQL – https://self-learning.ru/courses/t-sql
На курсах используется моя авторская последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL. Каждый курс включает огромное количество материалов: видео, текстовый материал, тесты, домашние задания, скрипты, а также сертификат о прохождении.
На курсах Вы можете заниматься в комфортном для себя темпе не выходя из дома в любое удобное для Вас время.