
Приветствую всех посетителей сайта Info-Comp.ru! В этом материале мы с Вами подробно рассмотрим транзакции языка T-SQL, Вы узнаете, что это такое, для чего они нужны, а также какие команды управления транзакциями существуют в T-SQL.

Заметка! T-SQL – это расширение языка SQL, реализованное в Microsoft SQL Server. Более подробно об этом можете почитать в статье – Что такое T-SQL. Подробное описание для начинающих.
- Транзакции в T-SQL
- Свойства транзакции
- Команды управления транзакциями в T-SQL
- Примеры транзакций в T-SQL
- Исходные данные для примеров
- Простой пример транзакции в T-SQL
- Пример транзакции в T-SQL с обработкой ошибок
- Уровни изоляции транзакций в T-SQL
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
- SNAPSHOT и READ COMMITTED SNAPSHOT
- Побочные эффекты параллелизма
- Включение уровня изоляции в T-SQL
Транзакции в T-SQL
Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе, или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены. Другими словами, если одна команда или инструкция внутри транзакции завершилась с ошибкой, то все, что было отработано перед ней, также отменяется, даже если предыдущие команды завершились успешно.
Транзакции очень полезны и просто незаменимы в тех случаях, когда Вам необходимо реализовывать бизнес логику в базе данных Microsoft SQL Server, которая предполагает многошаговые операции, где каждый шаг логически связан с другими шагами.
По сути каждая отдельная инструкция языка T-SQL является транзакцией, это называется «Автоматическое принятие транзакций» или «Неявные транзакции», но также есть и явные транзакции, это когда мы сами явно начинаем транзакцию и также явно заканчиваем ее, т.е. делаем все это с помощью специальных команд.
Чтобы понять, как работают транзакции и для чего они нужны, давайте рассмотрим классический пример, который наглядно показывает необходимость использования транзакций.
Допустим, у Вас есть хранимая процедура, которая осуществляет перевод средств с одного счета на другой, соответственно, как минимум у Вас будет две операции в этой процедуре, снятие средств, и зачисление средств, например, две инструкции UPDATE.
Но в каждой из этих операций может возникнуть ошибка и инструкция не выполнится. А теперь представьте, что первая инструкция снимает деньги, она выполнилась успешно, вторая инструкция зачисляет деньги и в ней возникла ошибка, без транзакции снятые деньги просто потеряются, так как они никуда не будут зачислены.
Чтобы этого не допустить, все SQL инструкции, которые логически что-то объединяет, в данном случае все операции, связанные с переводом средств, пишут внутри транзакции, и тогда, если наступит подобная ситуация, все изменения будут отменены, т.е. деньги вернутся обратно на счет.
Транзакции можно сочетать с обработкой и перехватом ошибок TRY…CATCH, иными словами, Вы отслеживаете ошибки в Вашем блоке инструкций и если они появляются, то в блоке CATCH Вы откатываете транзакцию, т.е. отменяете все изменения, которые были успешно выполнены до возникновения ошибки в транзакции.
Транзакции – это отличный механизм обеспечения целостности данных.
Свойства транзакции
У транзакции есть 4 очень важных свойства:
- Атомарность – все команды в транзакции либо полностью выполняются, и соответственно, фиксируются все изменения данных, либо ничего не выполняется и ничего не фиксируется;
- Согласованность – данные, в случае успешного выполнения транзакции, должны соблюдать все установленные правила в части различных ограничений, первичных и внешних ключей, определенных в базе данных;
- Изоляция – механизм предоставления доступа к данным. Транзакция изолирует данные, с которыми она работает, для того чтобы другие транзакции получали только согласованные данные;
- Надежность – все внесенные изменения фиксируются в журнале транзакций и данные считаются надежными, если транзакция была успешно завершена. В случае сбоя SQL Server сверяет данные, записанные в базе данных, с журналом транзакций, если есть успешно завершенные транзакции, которые не закончили процесс записи всех изменений в базу данных, они будут выполнены повторно. Все действия, выполненные не подтвержденными транзакциями, отменяются.
Заметка! Чем отличаются функции от хранимых процедур в T-SQL.
Команды управления транзакциями в T-SQL
В T-SQL для управления транзакциями существуют следующие основные команды:
- BEGIN TRANSACTION (можно использовать сокращённую запись BEGIN TRAN) – команда служит для определения начала транзакции. В качестве параметра этой команде можно передать и название транзакции, полезно, если у Вас есть вложенные транзакции;
- COMMIT TRANSACTION (можно использовать сокращённую запись COMMIT TRAN) – с помощью данной команды мы сообщаем SQL серверу об успешном завершении транзакции, и о том, что все изменения, которые были выполнены, необходимо сохранить на постоянной основе;
- ROLLBACK TRANSACTION (можно использовать сокращённую запись ROLLBACK TRAN) – служит для отмены всех изменений, которые были внесены в процессе выполнения транзакции, например, в случае ошибки, мы откатываем все назад;
- SAVE TRANSACTION (можно использовать сокращённую запись SAVE TRAN) – данная команда устанавливает промежуточную точку сохранения внутри транзакции, к которой можно откатиться, в случае возникновения необходимости.
Примеры транзакций в T-SQL
Давайте рассмотрим примеры транзакций, реализованные на языке T-SQL.
Исходные данные для примеров
Но сначала нам необходимо создать тестовые данные для нашего примера.
Для этого выполните следующую инструкцию.
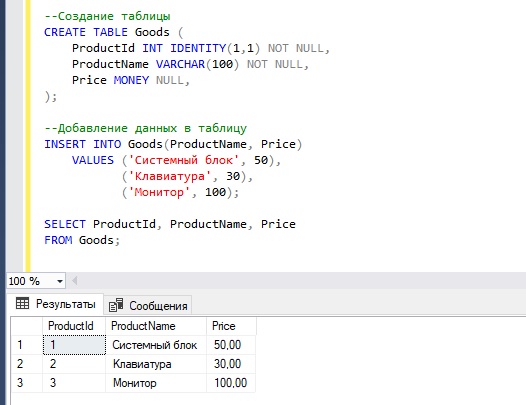
--Создание таблицы
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
--Добавление данных в таблицу
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 50),
('Клавиатура', 30),
('Монитор', 100);
SELECT ProductId, ProductName, Price
FROM Goods;
Заметка! Создание таблиц в Microsoft SQL Server (CREATE TABLE) – подробная инструкция.
Простой пример транзакции в T-SQL
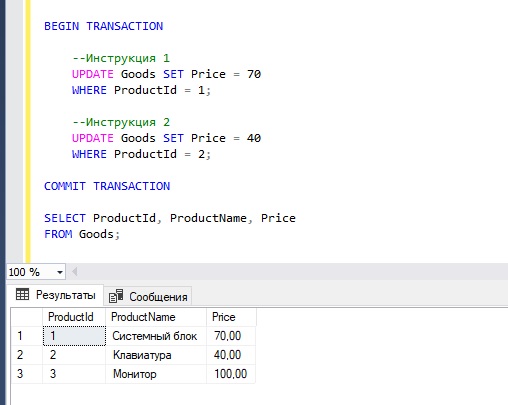
В данном примере у нас всего две инструкции, которые изменяют данные, но допустим, что они взаимосвязаны, т.е. они обе обязательно должны выполниться вместе или не выполниться также вместе.
Поэтому мы решили эти инструкции объединить в одну транзакцию.
Сначала мы открываем транзакцию командой BEGIN TRANSACTION, далее пишем все необходимые инструкции, которые мы хотим объединить в транзакцию.
После этого командой COMMIT TRANSACTION мы сохраняем все внесенные изменения.
В данном случае у нас нет никаких ошибок, все инструкции выполнились успешно. Как результат, транзакция завершена также успешно и все изменения сохранены на постоянной основе командой COMMIT TRANSACTION.
BEGIN TRANSACTION --Инструкция 1 UPDATE Goods SET Price = 70 WHERE ProductId = 1; --Инструкция 2 UPDATE Goods SET Price = 40 WHERE ProductId = 2; COMMIT TRANSACTION SELECT ProductId, ProductName, Price FROM Goods;
Однако, если в любой из инструкций возникнет ошибка, транзакция не завершится, и все изменения не сохранятся.
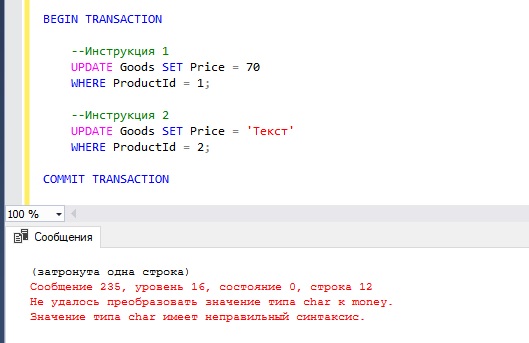
При этом, стоит помнить о том, что ошибки с определённым уровнем серьезности, например, ошибки, связанные с нарушением ограничений, не влекут за собой автоматический откат всех изменений внесенных текущей транзакцией, поэтому всегда необходимо использовать или инструкцию SET XACT_ABORT ON, или обработку ошибок (допускается и совместное использование).
Например, если во второй инструкции мы попытаемся записать в столбец Price какое-нибудь текстовое значение, то у нас возникнет ошибка, и изменения, внесённые первой инструкцией, не зафиксируются на постоянной основе.
Пример транзакции в T-SQL с обработкой ошибок
В языке T-SQL существует механизм перехвата и обработки ошибок – конструкция TRY… CATCH.
Эту конструкцию можно использовать для отслеживания появления возможных ошибок внутри транзакции и в случае появления таких ошибок предпринять определенные действия.
Сначала мы открываем блок для обработки ошибок, затем открываем транзакцию командой BEGIN TRANSACTION, далее пишем наши инструкции, например, те же самые две инструкции UPDATE.
После этого закрываем блок TRY, открываем блок CATCH, в котором в случае возникновения ошибки мы откатываем все изменения командой ROLLBACK TRANSACTION. Также мы принудительно завершаем нашу инструкцию командой RETURN.
Если ошибок нет, то в блок CATCH мы, соответственно, не попадаем и у нас выполнится команда COMMIT TRANSACTION, которая сохранит все изменения.
В этом примере нет ошибок, поэтому транзакция завершена успешно.
Заметка! Обработка ошибок в языке T-SQL – конструкция TRY CATCH.
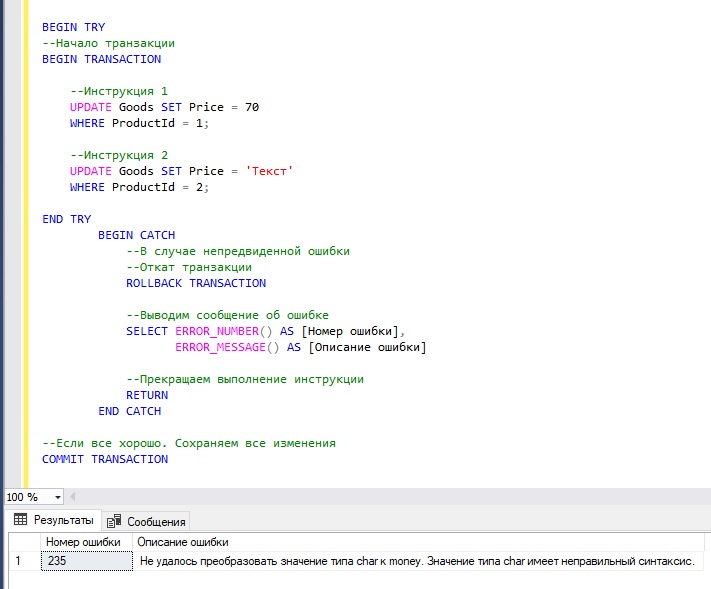
BEGIN TRY
--Начало транзакции
BEGIN TRANSACTION
--Инструкция 1
UPDATE Goods SET Price = 70
WHERE ProductId = 1;
--Инструкция 2
UPDATE Goods SET Price = 40
WHERE ProductId = 2;
END TRY
BEGIN CATCH
--В случае непредвиденной ошибки
--Откат транзакции
ROLLBACK TRANSACTION
--Выводим сообщение об ошибке
SELECT ERROR_NUMBER() AS [Номер ошибки],
ERROR_MESSAGE() AS [Описание ошибки]
--Прекращаем выполнение инструкции
RETURN
END CATCH
--Если все хорошо. Сохраняем все изменения
COMMIT TRANSACTION
GO
SELECT ProductId, ProductName, Price
FROM Goods;
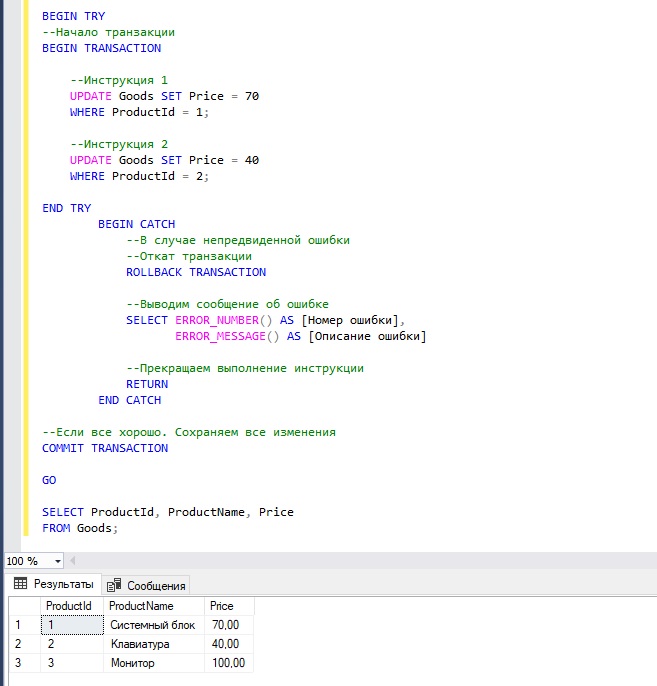
А в этом примере мы намерено допускаем ошибку во второй инструкции. Поэтому управление передается в блок CATCH, где мы откатываем все изменения, возвращаем номер и описание ошибки и принудительно завершаем всю инструкцию командой RETURN.
Первая инструкция отработала нормально, но ее изменения не были сохранены, так как вторая инструкция выполнена с ошибкой.
Заметка! Чем отличается инструкция THROW от RAISERROR в T-SQL.
Уровни изоляции транзакций в T-SQL
Во время выполнения транзакции все данные, над которыми производятся изменения, блокируются, до завершения транзакции, так как, когда один процесс изменяет данные, другой процесс не может одновременно изменять их. В SQL сервере существует механизм, который блокирует (изолирует) данные во время выполнения транзакции. У данного механизма есть несколько уровней изоляции, каждый из которых определяет степень блокировки данных.
Давайте подробней рассмотрим уровни изоляции.
READ UNCOMMITTED
Самый низкий уровень, при котором SQL сервер разрешает так называемое «грязное чтение». Грязным чтением называют считывание неподтвержденных данных, иными словами, если транзакция, которая изменяет данные, не завершена, другая транзакция может получить уже измененные данные, хотя они еще не зафиксированы и могут отмениться.
READ COMMITTED
Этот уровень уже запрещает грязное чтение, в данном случае все процессы, запросившие данные, которые изменяются в тот же момент в другой транзакции, будут ждать завершения этой транзакции и подтверждения фиксации данных. Данный уровень по умолчанию используется SQL сервером.
REPEATABLE READ
На данном уровне изоляции запрещается изменение данных между двумя операциями чтения в одной транзакции. Здесь происходит запрет на так называемое «неповторяющееся чтение» или «несогласованный анализ». Другими словами, если в одной транзакции есть несколько операций чтения, данные будут блокированы и их нельзя будет изменить в другой транзакции. Таким образом, Вы избежите ситуации, когда вначале транзакции Вы запросили данные, провели их анализ (некое вычисление), в конце транзакции запросили те же самые данные, а они уже отличаются от первоначальных, так как они были изменены другой транзакцией.
Также уровень REPEATABLE READ, как и остальные, запрещает «Потерянное обновление» – это когда две транзакции сначала считывают одни и те же данные, а затем изменяют их на основе неких вычислений, в результате обе транзакции выполнятся, но данные будут те, которая зафиксировала последняя операция обновления. Это происходит потому, что данные в операциях чтения в начале этих транзакций не были заблокированы.
SERIALIZABLE
Данный уровень исключает чтение «фантомных» записей. Фантомные записи – это те записи, которые появились между началом и завершением транзакции. Иными словами, в начале транзакции Вы запросили определенные данные, в конце транзакции Вы запрашиваете их снова с тем же фильтром, но там уже есть и новые данные, которые добавлены другой транзакцией. Более низкие уровни изоляции не блокировали строки, которых еще нет в таблице, данный уровень блокирует все строки, соответствующие фильтру запроса, с которыми будет работать транзакция, как существующие, так и те, что могут быть добавлены.
SNAPSHOT и READ COMMITTED SNAPSHOT
Также существуют уровни изоляции, алгоритм которых основан на версиях строк, это
- SNAPSHOT
- READ COMMITTED SNAPSHOT
Иными словами, SQL Server делает снимок и хранит последние версии подтвержденных строк. В данном случае, клиенту не нужно ждать снятия блокировок, пока одна транзакция изменит данные, он сразу получает последнюю версию подтвержденных строк. Следует отметить, что уровни изоляции, основанные на версиях строк, замедляют операции обновления и удаления, так как перед этими операциями сервер делает и копирует снимок строк во временную базу данных.
SNAPSHOT – уровень хранит строки, подтверждённые на момент начала транзакции, соответственно, именно эти строки будут считаны в случае обращения к ним из другой транзакции. Данный уровень исключает повторяющееся и фантомное чтение примерно так же, как уровень SERIALIZABLE.
READ COMMITTED SNAPSHOT – этот уровень изоляции работает практически так же, как уровень SNAPSHOT, с одним отличием, он хранит снимок строк, которые подтверждены на момент запуска команды, а не транзакции, как в SNAPSHOT.
Заметка! Обзор Azure Data Studio. Что это за инструмент и для чего он нужен.
Побочные эффекты параллелизма
На основе вышеизложенного мы можем выделить несколько побочных эффектов, которые могут возникнуть в результате параллельного использования данных:
- Потерянное обновление (Lost Update) – при одновременном изменении данных разными транзакциями одно из изменений будет потеряно;
- Грязное чтение (Dirty Read) – чтение неподтвержденных данных;
- Неповторяющееся чтение (Non-Repeatable Read) – чтение измененных данных в рамках одной транзакции;
- Фантомное чтение (Phantom Reads) – чтение записей, которые появились между началом и завершением транзакции.
Каждый из уровней изоляции устраняет определенные побочные эффекты. В таблице ниже приведены сводные данные.
| Побочный эффект / Уровень изоляции | Потерянное обновление | Грязное чтение | Неповторяющееся чтение | Фантомные записи |
| READ UNCOMMITTED | Устраняет | Не устраняет | Не устраняет | Не устраняет |
| READ COMMITTED | Устраняет | Устраняет | Не устраняет | Не устраняет |
| REPEATABLE READ | Устраняет | Устраняет | Устраняет | Не устраняет |
| SERIALIZABLE | Устраняет | Устраняет | Устраняет | Устраняет |
| SNAPSHOT | Устраняет | Устраняет | Устраняет | Устраняет |
| READ COMMITTED SNAPSHOT | Устраняет | Устраняет | Устраняет | Устраняет |
Включение уровня изоляции в T-SQL
Для того чтобы включить тот или иной уровень изоляции для всей сессии, необходимо выполнить команду SET TRANSACTION ISOLATION LEVEL и указать название уровня изоляции.
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Также для уровней SNAPSHOT и READ COMMITTED SNAPSHOT предварительно необходимо включить параметр базы данных ALLOW_SNAPSHOT_ISOLATION для уровня изоляции SNAPSHOT и READ_COMMITTED_SNAPSHOT для уровня READ COMMITTED SNAPSHOT.
Например
ALTER DATABASE TestDB SET ALLOW_SNAPSHOT_ISOLATION ON;
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
На сегодня это все, надеюсь, материал был Вам полезен, до новых встреч!






