
В языке Transact-SQL существует очень полезный и мощный инструмент для формирования различных аналитических отчетов – это инструкция OVER, которая работает совместно с так называемыми «оконными функциями», именно об этом мы сегодня с Вами и поговорим.

Инструкция OVER в Transact-SQL
OVER – это инструкция T-SQL, которая определяет окно для применения оконной функции. «Окно» в Microsoft SQL Server – это контекст, в котором работает функция с определённым набором строк, относящихся к текущей строке.
Оконная функция – это функция, которая соответственно работает с окном, т.е. набором строк, и возвращает значение на основе неких вычислений.
Как я уже отметил, оконные функции используют в аналитических отчетах, например, для вычисления каких-то статистических значений (суммы, скользящие средние, промежуточные итоги и так далее) для каждой строки результирующего набора данных.
Честно скажу это очень удобный и полезный функционал Microsoft SQL Server. Впервые поддержка оконных функций появилась в версии Microsoft SQL Server 2005, в которой была реализованы базовая функциональность. В Microsoft SQL Server 2012 функционал оконных функций был расширен, и теперь он с лёгкостью решает много задач, которые до этого решались написанием дополнительного, в некоторых случаях, сложного, непонятного кода (вложенные запросы и т.д.).
Упрощенный синтаксис инструкции OVER
Оконная функция (столбец для вычислений) OVER (
[PARTITION BY столбец для группировки]
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы]
)
В выражении для ограничения строк в группе можно использовать следующие ключевые слова:
- ROWS – ограничивает строки;
- RANGE — логически ограничивает строки за счет указания диапазона значений в отношении к значению текущей строки;
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы. Данная инструкция используется только как начальная точка окна;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы, соответственно, она может быть указана только как конечная точка окна;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке, она может быть задана как начальная или как конечная точка;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна, при этом верхняя граница не может быть меньше нижней границы;
- «Значение» PRECEDING – определяет число строк перед текущей строкой. Эта инструкция не допускается в предложении RANGE;
- «Значение» FOLLOWING — определяет число строк после текущей строки. Если FOLLOWING используется как начальная точка окна, то конечная точка должна быть также указана с помощью FOLLOWING. Эта инструкция не допускается в предложении RANGE.
Примечание! Чтобы указать выражение для дополнительного ограничения строк (ROWS или RANGE) в окне должна быть указана инструкция ORDER BY.
А сейчас давайте рассмотрим оконные функции, которые существуют в Transact-SQL.
Заметка! Функции TRIM, LTRIM и RTRIM в T-SQL – описание, отличия и примеры.
Оконные функции в Transact-SQL
В T-SQL оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать несколько оконных функций. Если инструкция PARTITION BY не указана, функция будет обрабатывать все строки результирующего набора. Некоторые функции не поддерживают инструкцию ORDER BY, ROWS или RANGE.
Исходные данные для примеров
Перед тем как перейти к рассмотрению использования оконных функций, давайте сначала создадим тестовые данные, для того чтобы выполнять примеры.
В качестве сервера у меня будет выступать Microsoft SQL Server 2016 Express.
Допустим, у нас будет таблица TestTable, которая содержит список товаров с некоторыми характеристиками.
--Создание таблицы
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryId] [INT] NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [Money] NULL
)
GO
--Вставляем в таблицу данные
INSERT INTO TestTable
VALUES (1, 'Клавиатура', 100),
(1, 'Мышь', 50),
(1, 'Системный блок', 200),
(1, 'Монитор', 250),
(2, 'Телефон', 300),
(2, 'Планшет', 500)
SELECT * FROM TestTable
Агрегатные оконные функции
Агрегатные функции – это функции, которые выполняют на наборе данных вычисления и возвращают итоговое значение. Агрегатные функции, я думаю, всем известны — это, например:
- SUM – возвращает сумму значений в столбце;
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются). Если написать COUNT(*), то будут учитываться все записи, т.е. все строки. Возвращает тип данных INT;
- COUNT_BIG – работает также как COUNT, только возвращает тип данных BIGINT.
Обычно агрегатные функции используются в сочетании с инструкцией GROUP BY, которая группирует строки, но их также можно использовать и без GROUP BY, например, с использованием инструкции OVER, и в данном случае они будут вычислять значения в определённом окне (наборе данных) для каждой текущей строки. Это очень удобно, если Вам необходимо получить какую-нибудь величину по отношению к общей сумме, например.
Пример использования агрегатных оконных функций с инструкцией OVER.
В этом примере продемонстрировано простое применение некоторых агрегатных оконных функций.
SELECT ProductId, ProductName, CategoryId, Price,
SUM(Price) OVER (PARTITION BY CategoryId) AS [SUM],
AVG(Price) OVER (PARTITION BY CategoryId) AS [AVG],
COUNT(Price) OVER (PARTITION BY CategoryId) AS [COUNT],
MIN(Price) OVER (PARTITION BY CategoryId) AS [MIN],
MAX(Price) OVER (PARTITION BY CategoryId) AS [MAX]
FROM TestTable
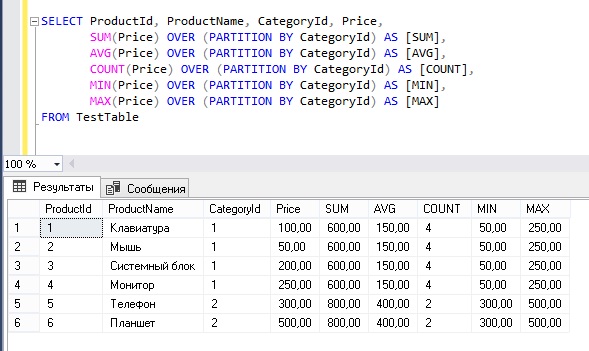
Как видите, у нас вывелись все строки, включая столбцы с агрегированными данными, сгруппированными по категории.
Ранжирующие оконные функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в группе. Например, их можно использовать для того, чтобы пронумеровать строки по группам или выставить ранг и составить рейтинг.
В Microsoft SQL Server существуют следующие ранжирующие функции:
- ROW_NUMBER – функция возвращает номер строки, используется для нумерации строк в секции результирующего набора;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая возвращает результирующий набор, разделённый на группы по определенному столбцу.
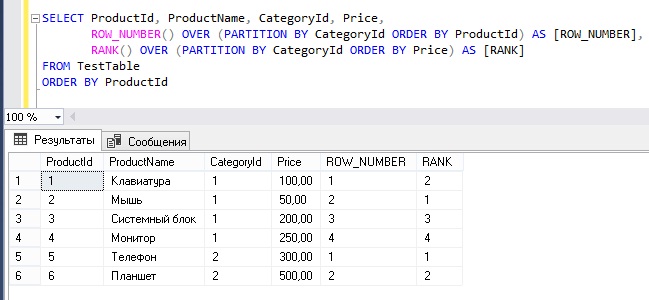
Пример использования ранжирующих оконных функций с инструкцией OVER.
В данном примере мы пронумеруем строки в каждой категории, при этом используем сортировку по столбцу ProductId, а также выставим ранг каждому товару в категории на основе его цены.
SELECT ProductId, ProductName, CategoryId, Price,
ROW_NUMBER() OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [ROW_NUMBER],
RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [RANK]
FROM TestTable
ORDER BY ProductId
Более детально про ранжирующие функции мы говорили в материале – Функции ранжирования и нумерации в Transact-SQL.
Оконные функции смещения
Функции смещения – это функции, которые позволяют перемещаться и, соответственно, обращаться к разным строкам в наборе данных (окне) относительно текущей строки или просто обращаться к значениям в начале или в конце окна. Эти функции появились в Microsoft SQL Server 2012.
К функциям смещения в T-SQL относятся:
- LEAD – функция обращается к данным из следующей строки набора данных. Ее можно использовать, например, для того чтобы сравнить текущее значение строки со следующим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- LAG – функция обращается к данным из предыдущей строки набора данных. В данном случае функцию можно использовать для того, чтобы сравнить текущее значение строки с предыдущим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE — функция возвращает первое значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть;
- LAST_VALUE — функция возвращает последнее значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть.
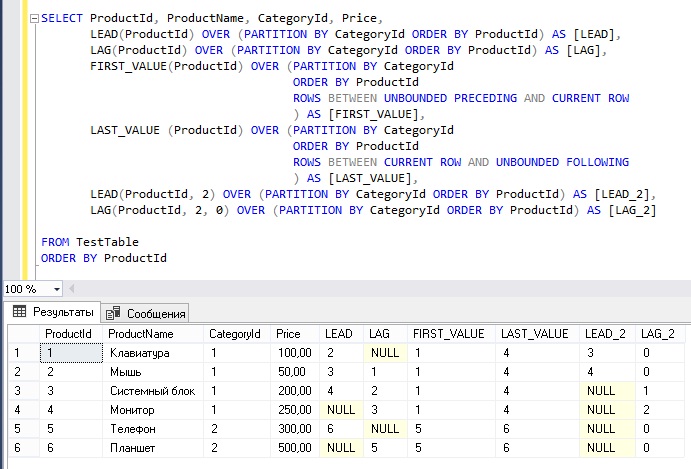
Пример использования оконных функций смещения в T-SQL.
В этом примере сначала мы вернем следующее и предыдущее значение идентификатора товара в категории. Затем с помощью FIRST_VALUE и LAST_VALUE получим первое и последнее значение идентификатора товара в категории, при этом в качестве примера я покажу, как используется синтаксис дополнительного ограничения строк. А потом, используя необязательные параметры функций LEAD и LAG, мы сместимся уже на 2 строки относительно текущей, при этом, если после смещения функцией LAG такой строки не окажется, нам вернется 0, так как мы укажем третий необязательный параметр со значением 0.
SELECT ProductId, ProductName, CategoryId, Price,
LEAD(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD],
LAG(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG],
FIRST_VALUE(ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS [FIRST_VALUE],
LAST_VALUE (ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS [LAST_VALUE],
LEAD(ProductId, 2) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD_2],
LAG(ProductId, 2, 0) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG_2]
FROM TestTable
ORDER BY ProductId
Аналитические оконные функции
Здесь я перечислю так называемые функции распределения, которые возвращают информацию о распределении данных. Эти функции очень специфичны и в основном используются для статистического анализа, к ним относятся:
- CUME_DIST — вычисляет и возвращает интегральное распределение значений в наборе данных. Иными словами, она определяет относительное положение значения в наборе;
- PERCENT_RANK — вычисляет и возвращает относительный ранг строки в наборе данных;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
У функций PERCENTILE_CONT и PERCENTILE_DISC синтаксис немного отличается, столбец, по которому сортировать данные, указывается с помощью ключевого слова WITHIN GROUP.
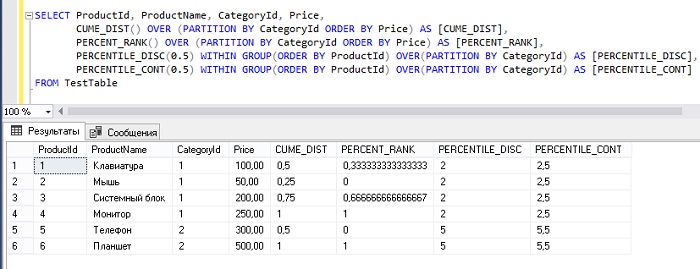
Пример использования аналитических оконных функций в T-SQL.
SELECT ProductId, ProductName, CategoryId, Price,
CUME_DIST() OVER (PARTITION BY CategoryId ORDER BY Price) AS [CUME_DIST],
PERCENT_RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [PERCENT_RANK],
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_DISC],
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_CONT]
FROM TestTable
Оконные функции языка T-SQL мы рассмотрели, некоторые из них, как я уже говорил, очень полезны и значительно упрощают написание SQL запросов, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, у меня на этом все, пока!
Заметка! Все возможности языка SQL и T-SQL очень подробно рассматриваются в моих видеокурсах по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL в Microsoft SQL Server.







Спасибо за статью! Четко и понятно все изложено.
И Вам спасибо за отзыв!
Отличная статья. Спасибо
Приглашаю всех желающих пройти мои онлайн-курсы по изучению языка T-SQL – https://self-learning.ru/courses/t-sql
На курсах используется моя авторская последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL. Каждый курс включает огромное количество материалов: видео, текстовый материал, тесты, домашние задания, скрипты, а также сертификат о прохождении.
На курсах Вы можете заниматься в комфортном для себя темпе не выходя из дома в любое удобное для Вас время.
Очень прозрачно объяснено! Спасибо
«Окно» — это контекст, в котором работает функция с определенным набором строк, относящихся к текущей строке.
Я эту фразу пытаюсь «вкурить». Не могу логически понять, что значит «с определенный набор строк, относящихся к текущей строке»?