
Приветствую Вас на сайте Info-Comp.ru! Сегодня мы с Вами разберем внутреннюю архитектуру обработки SQL запросов в Microsoft SQL Server.
Дело в том, что между тем моментом, когда мы нажали кнопку «Выполнить», т.е. послали SQL запрос, и моментом, когда мы увидели запрашиваемые данные, внутри SQL Server выполняется огромная, многоэтапная работа, о которой полезно знать всем разработчикам и администраторам Microsoft SQL Server.
Иными словами, сегодня мы поговорим о том, что именно происходит, так сказать, за «кулисами» в том момент, когда мы посылаем запрос на SQL Server.

Введение в архитектуру обработки запросов в SQL Server
Многие начинающие разработчики думают, что, когда мы запускаем SQL запрос на выполнение, Microsoft SQL Server просто парсит текст запроса и сразу возвращает нам данные. Однако это не так.
SQL Server перед тем, как вернуть нам результат, т.е. данные, выполняет достаточно много сложных различных операций, иными словами, данные нам возвращаются только после работы сложного внутреннего механизма, о котором мы сейчас и поговорим, т.е. о том, что на самом деле происходит с момента, когда мы нажали кнопку «Выполнить» и послали SQL запрос, до того, когда мы увидели запрашиваемые данные.
Итак, внутри SQL Server работает сложный механизм, работу которого обеспечивают несколько специально созданных так называемых «движков», каждый из которых отвечает за определенный участок работы.
За обработку SQL запросов в Microsoft SQL Server отвечает движок, который называется – Relational Engine.
Заметка! Обзор инструментов для работы с Microsoft SQL Server.
Relational Engine
Relational Engine – это компонент Microsoft SQL Server, который отвечает за обработку SQL запросов.
На входе данный движок принимает текст SQL запроса, а на выходе отдает данные, которые мы запрашивали с помощью этого SQL запроса.
Relational Engine включает несколько этапов обработки SQL запроса. Можно выделить 3 основных, глобальных этапа:
- Query Parsing
- Query Optimization
- Query Execution
Обязательно стоит отметить, что каждый из этих этапов включает несколько дополнительных этапов, иными словами, на каждом этапе запускается несколько процессов, отвечающих за ту или иную обработку SQL запроса.
Давайте чуть более подробно поговорим о каждом этапе обработки SQL запроса компонентом Relational Engine, таким образом, Вы будете понимать, какие процессы запускаются, когда мы выполняем SQL запрос в Microsoft SQL Server.
Query Parsing
Parsing
На данном этапе выполняются следующие действия:
- Чтение и разбор текста запроса
- Генерирование хэша по тексту запроса
- Проверка кэша планов, т.е. поиск подходящего плана в кэше. Иными словами, если для данного текста запроса ранее уже был сформирован план выполнения, то необязательно выполнять все последующие действия, так как можно взять план из кэша
- Синтаксический анализ
- Построение дерева логических операторов
Algebrizer
На данном этапе происходит так называемый Binding – это проверка на существования объектов базы данных, столбцов в таблицах, которые указаны в запросе, а также сопоставление каждого объекта дерева с реальным объектом системного каталога.
Результатом этапа Query Parsing является Query Tree (дерево запроса, т.е. дерево логических шагов, необходимых для преобразования исходных данных в формат, требуемый результирующему набору).
Query Optimization
Query Optimization – это как раз тот самый, всем известный «Оптимизатор запросов», основной функцией которого является построение плана выполнения запроса.
План выполнения запроса – это набор конкретных действий, выполнение которых приведет SQL запрос к итоговому результату.
Иными словами, план выполнения запроса – это то, как именно будет выполняться пользовательский запрос, т.е. как именно будет осуществляться доступ к исходным данных, в каком порядке, какие конкретные методы будут использоваться для извлечения данных из каждой таблицы, какие конкретные методы будут использованы для вычислений, фильтрации, статистической обработки и сортировки данных.
А все дело в том, что SQL Server может выполнить запрос и получить одни и те же данные разными способами, т.е. набор физических операций в различных условиях будет отличаться.
Таким образом, работа оптимизатора заключается как раз в создании оптимального плана выполнения запроса, при котором результат возвращается быстрее всего и задействовано меньше всего ресурсов.
Заметка! Более подробно о плане выполнения запроса в Microsoft SQL Server мы поговорили в отдельном материале. План выполнения запроса в Microsoft SQL Server.
Данный этап, т.е. процесс оптимизации запроса, включает несколько фаз, в частности:
- Simplification
- Trivial Plan Optimization
- Full Optimization
- Search 0
- Search 1
- Search 2
Simplification
На данном этапе происходит упрощение дерева запроса, например:
- удаление ненужных соединений
- разворачивание подзапросов в соединения (если это возможно)
- условия фильтрации могут быть перемещены в начало дерева запроса, чтобы отфильтровать данные как можно раньше
Trivial Plan Optimization
Это этап поиска тривиального плана, т.е. если запрос может быть решен единственным способом, то значит, запрос удовлетворяет условию тривиального плана и никакие правила оптимизации применять не стоит.
Full Optimization: Search 0
На этом этапе оптимизатор ищет хороший план за минимальное время. Но данный этап может быть пропущен, и оптимизатор сразу может перейти к следующему этапу, если запрос не удовлетворяет определенным условиям.
Full Optimization: Search 1
На данном этапе используются дополнительные правила преобразования и некоторые возможные перестановки вариантов соединения данных. Если после генерации плана на этой стадии, план все еще недостаточно хорош, то данная стадия повторяется с целью поиска параллельного плана. После чего два плана сравниваются, и для оценки выбирается лучший из них. Если этот лучший план все еще не проходит внутренние пороги оптимизатора, то управление переходит к следующей фазе.
Full Optimization: Search 2
Это самый последний этап оптимизации, на котором в любом случае будет найден тот или иной план выполнения запроса.
На этапе Query Optimization перед тем, как передать найденный, т.е. итоговый план запроса на выполнение, этот план помещается в кэш планов, для случаев, если этот же запрос в ближайшее время будет использован повторно.
Заметка! Статистика в Microsoft SQL Server – что это такое и для чего она нужна.
Query Execution
Результатом предыдущего этапа является план выполнения запроса, т.е. на входе в данный этап мы имеем готовый план выполнения, который необходимо реализовать.
Query Execution предназначен как раз для этого, т.е. на данном этапе реализуется план выполнения запроса.
Выглядит это примерно следующим образом, в ходе выполнения плана и обработки конкретных шагов Query Execution запрашивает у подсистемы хранилища (Storage Engine) данные из базовых таблиц, которые требуются для формирования результирующего набора данных.
Затем он преобразует эти данные в формат результирующего набора данных и возвращает этот набор клиенту.
Все действия, связанные с блокировками, с записями в файл данных и журнал транзакций, выполняются на стороне подсистемы хранилища, т.е. в Storage Engine.
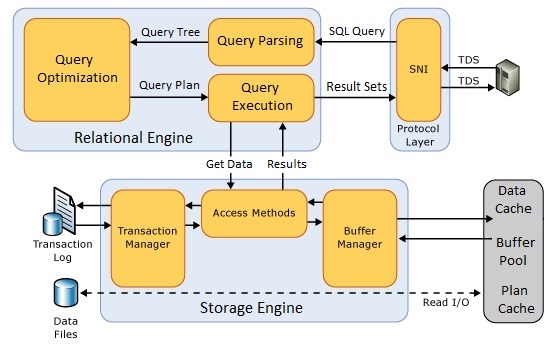
Выводы (общая схема)
Таким образом, мы понимаем, что начиная с момента, когда SQL запрос поступил на сервер, внутри Microsoft SQL Server запускается сложный механизм, который обрабатывает этот SQL запрос.
Иными словами, между тем моментом, когда мы послали SQL запрос на сервер и моментом, когда мы увидели запрашиваемые данные, будет выполнена огромная работа.
Чтобы подытожить все вышесказанное, давайте посмотрим на схему, на которой изображено верхнеуровневое представление всего процесса обработки SQL запроса в Microsoft SQL Server.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!






