
Всем привет! Сегодня мы с Вами поговорим о том, что же такое статистика в Microsoft SQL Server, Вы узнаете, для чего она нужна, какую информацию она включает, какие параметры базы данных влияют на работу статистики и многое другое.

- Что такое статистика в Microsoft SQL Server
- Отфильтрованная статистика
- Разделы статистики
- Заголовок
- Плотность
- Гистограмма
- Пример статистики в Microsoft SQL Server
- Параметры базы данных SQL Server, связанные со статистикой
- Параметр AUTO_CREATE_STATISTICS
- Параметр AUTO_UPDATE_STATISTICS
- Параметр AUTO_UPDATE_STATISTICS_ASYNC
Что такое статистика в Microsoft SQL Server
Начать хотелось бы с того, что когда мы запускаем SQL запрос на выполнение, Microsoft SQL Server, перед тем как вернуть нам результат, т.е. данные, выполняет достаточно много сложных различных операций. Иными словами, SQL Server не просто читает текст запроса и сразу бежит за данными.
На самом деле внутри SQL Server работает сложный многоэтапный механизм, который включает и синтаксический анализ, и проверку существования объектов базы данных, которые указаны в запросе, а также процесс формирования так называемого «плана выполнения запроса», который представляет собой набор физических операций, в результате выполнения которых мы получим нужные нам данные.
И здесь у SQL Server возникает проблема, и заключается она в том, что одни и те же данные можно получить по-разному, т.е. набор физических операций в различных условиях будет отличаться. Это связанно с тем, что существует много различных алгоритмов обработки данных, каждый из которых будет работать эффективнее при определённых условиях, а на эти условия оказывает влияние очень много факторов, начиная от конфигурации системы и доступных ресурсов, и заканчивая наличием индексов и количеством данных.
Таким образом, «оптимизатор запросов» (именно так называется компонент, который формирует план выполнения запроса) перед тем, как сформировать итоговый план выполнения запроса, анализирует много различных факторов, и перебирает много различных планов выполнения, чтобы в конечном итоге сформировать оптимальный план. И здесь стоит отметить, что оптимизатор ищет именно оптимальный, так называемый «достаточно хороший план» выполнения запроса, дело в том, что на поиск самого лучшего плана оптимизатору может потребоваться очень много времени, т.е. в результате это может быть неэффективно, так как, допустим, оптимизатор может потратить 1 секунду на поиск самого лучшего плана, который выполнится за 0.1 секунды (т.е. суммарно запрос выполнится за 1.1 секунды), хотя, если оптимизатор не искал бы самый лучший план, он мог, например, за 0.1 секунды найти план, который выполнит запрос за 0.2 секунды (т.е. суммарно запрос выполнится за 0.3 секунды), что в конечном счете будет намного быстрее, чем при самом лучшем плане. Поэтому здесь нужен компромисс и оптимизатор ищет именно оптимальный план выполнения запроса.
Как было сказано, оптимизатор, при формировании плана, анализирует много различных факторов, в числе который немаловажную роль играет количество и распределение данных в таблицах.
И здесь возникает вопрос «как SQL Server получить эти сведения?». Собирать их при каждом запросе? Нет – это очень накладно, т.е. крайне неэффективно, поэтому SQL Server периодически собирает сведения о количестве и распределении данных в таблицах и хранит их в отдельном месте. И именно это и называется статистика.
Статистика – это статистические сведения о распределении значений в одном или нескольких столбцах таблицы или индексированного представления.
Оптимизатор запросов использует статистику для оценки кратности – числа строк в результатах запроса. Такая оценка кратности позволяет оптимизатору запросов создать оптимальный план запроса. Например, в зависимости от предикатов оптимизатор запросов может использовать оценку кратности, чтобы выбрать оператор Index Seek вместо оператора Index Scan, который потребляет больше ресурсов, если благодаря этому повысится производительность запроса.
SQL Server создает статистику автоматически для каждого индекса, при его создании, а также для отдельных столбцов, которые используются как аргументы поиска в предикатах запроса, однако в данном случае должен быть включён параметр базы данных AUTO_CREATE_STATISTICS (подробнее о параметрах базы данных, которые влияют на статистику, мы поговорим чуть позже). По умолчанию данный параметр включен, т.е. SQL Server настроен на автоматическое создание статистики. Однако стоит отметить, что он не влияет на создание статистики для индексов, т.е. даже если параметр AUTO_CREATE_STATISTICS выключен, статистика для индексов все равно будет создаваться.
- Работа со статистикой в Microsoft SQL Server. Часть 1 – Просмотр статистики
- Работа со статистикой в Microsoft SQL Server. Часть 2 – Создание и удаление статистики
- Работа со статистикой в Microsoft SQL Server. Часть 3 – Обновление статистики
Отфильтрованная статистика
Кроме обычной статистки, которая создается по полной таблице, существует также отфильтрованная статистика.
Отфильтрованная статистика – это статистика, созданная для определенного подмножества данных.
Отфильтрованная статистика может улучшить план выполнения запроса по сравнению со статистикой по полной таблице и тем самым повысить производительность запросов, которые выполняют выборку из четко определенных подмножеств данных, так как отфильтрованная статистика использует предикат фильтра для выбора подмножества данных, включенных в статистику.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Разделы статистики
Статистика включает 3 раздела.
Заголовок
Содержит общую информацию о статистике, такую как
| Имя столбца | Описание |
| Name | Имя объекта статистики |
| Update | Дата и время последнего обновления статистики |
| Rows | Общее число строк в таблице или индексированном представлении при последнем обновлении статистики. Если статистика отфильтрована или соответствует отфильтрованному индексу, количество строк может быть меньше, чем количество строк в таблице. |
| Rows Sampled | Общее количество строк, выбранных для статистических вычислений. Если число меньше, чем в столбце Rows, значит, статистика основана не на всех данных и может быть неточной. |
| Steps | Число шагов в гистограмме. Каждый шаг охватывает диапазон значений столбцов, за которым следует значение столбца, представляющее собой верхнюю границу. Шаги гистограммы определяются в первом ключевом столбце статистики. Максимальное число шагов – 200. |
| Density | Плотность. Рассчитывается как 1 / различающиеся значения для всех значений в первом ключевом столбце объекта статистики, исключая возможные значения гистограммы. Это значение плотности не используется оптимизатором запросов и отображается для обратной совместимости с версиями, выпущенными до SQL Server 2008. |
| Average Key Length | Среднее число байтов на значение для всех ключевых столбцов в объекте статистики. |
| String Index | Значение «Yes» указывает, что объект статистики содержит сводную строковую статистику, позволяющую уточнить оценку количества элементов для предикатов запроса, использующих оператор LIKE. |
| Filter Expression | Предикат для подмножества строк таблицы, включенных в объект статистики. NULL – неотфильтрованная статистика. |
| Unfiltered Rows | Общее количество строк в таблице перед применением критерия фильтра. Если Filter Expression имеет значение NULL, то столбец Unfiltered Rows совпадает со столбцом Rows. |
| Persisted Sample Percent | Процент материализованной выборки используется для обновлений статистики, где явно не указан процент выборки. Если значение равно нулю, процент материализованной выборки не устанавливается для этой статистики. Применимо к: SQL Server 2016 (13.x); с пакетом обновления 1 (SP1) и накопительным обновлением 4. |
Заметка! Обзор инструментов для работы с Microsoft SQL Server.
Плотность
Плотность – это показатель, который отражает, сколько уникальных значений содержится в столбце или наборе столбцов.
Иными словами
Плотность = 1 / Число различных значений столбца (столбцов)
Оптимизатор запросов использует плотности для улучшения оценки размерности для запросов, которые возвращают данные нескольких столбцов из одной таблицы или индексированного представления. По мере повышения плотности избирательность значения повышается.
Плотность содержит следующую информацию о статистике, называемую «Вектор плотностей».
| Имя столбца | Описание |
| All Density | Общая плотность. Равна 1 / различающиеся значения. В результатах отображаются плотности для каждого префикса столбцов объекта статистики, по одной строке на плотность. |
| Average Length | Средняя длина (в байтах) для хранения списка значений столбца для данного префикса столбца. Если каждому значению в списке (3, 5, 6), например, требуется по 4 байта, то длина составляет 12 байт. |
| Columns | Имена столбцов в префиксе, для которых отображаются значения «Общая плотность» и «Средняя длина». |
Вектор плотностей содержит по одной плотности для каждого префикса столбцов объекта статистики. Например, если объект статистики имеет ключевые столбцы ProductId, CategoryId и Price, плотность вычисляется для каждого из следующих префиксов столбцов.
| Набор столбцов | Префикс, по которому вычисляется плотность |
| ProductId | Строки с совпадающими значениями ProductId |
| ProductId, CategoryId | Строки с совпадающими значениями ProductId, CategoryId. |
| ProductId, CategoryId, Price | Строки с совпадающими значениями ProductId, CategoryId, Price |
Заметка! Транзакции в T-SQL – основы для новичков с примерами.
Гистограмма
Гистограмма – это распределение данных в первом ключевом столбце объекта статистики.
Она измеряет частоту появления каждого различающегося значения в наборе данных. Оптимизатор запросов вычисляет гистограмму для значений столбца в первом ключевом столбце объекта статистики, выбирая значения столбцов путем статистической выборки строк или полного просмотра всех строк в таблице или представлении. Если гистограмма создается на основе выбранного набора строк, то сохраняемые итоговые значения количества строк и количества различающихся значений являются приблизительными и не всегда выражаются целыми числами.
Примечание! Гистограммы в SQL Server создаются только для одного столбца, которым является первый столбец в наборе ключевых столбцов объекта статистики.
Чтобы создать гистограмму, оптимизатор запросов сортирует значения столбцов, вычисляет количество значений, совпадающих с каждым отдельным значением столбца, а затем осуществляет статистическую обработку значений столбцов с получением непрерывных шагов гистограммы, максимальное количество которых составляет 200. Каждый шаг гистограммы включает диапазон значений столбцов, за которым следует значение столбца, представляющее собой верхнюю границу. В этот диапазон входят все возможные значения столбца между граничными значениями, за исключением самих граничных значений. Наименьшим из отсортированных значений столбца является верхнее граничное значение первого шага гистограммы.
| Имя столбца | Описание |
| RANGE_HI_KEY | Верхнее граничное значение столбца для шага гистограммы. Это значение столбца называется также ключевым значением. |
| RANGE_ROWS | Предполагаемое количество строк, значение столбцов которых находится в пределах шага гистограммы, исключая верхнюю границу. |
| EQ_ROWS | Предполагаемое количество строк, значение столбцов которых равно верхней границе шага гистограммы. |
| DISTINCT_RANGE_ROWS | Предполагаемое количество строк с различающимся значением столбца в пределах шага гистограммы, исключая верхнюю границу. |
| AVG_RANGE_ROWS | Среднее количество строк с повторяющимися значениями столбца в пределах шага гистограммы, исключая верхнюю границу. Если значение DISTINCT_RANGE_ROWS больше 0, AVG_RANGE_ROWS вычисляется делением RANGE_ROWS на DISTINCT_RANGE_ROWS. Если значение DISTINCT_RANGE_ROWS равно 0, AVG_RANGE_ROWS возвращает значение 1 для шага гистограммы. |
Заметка! XACT_ABORT в T-SQL – что это такое и как использовать.
Пример статистики в Microsoft SQL Server
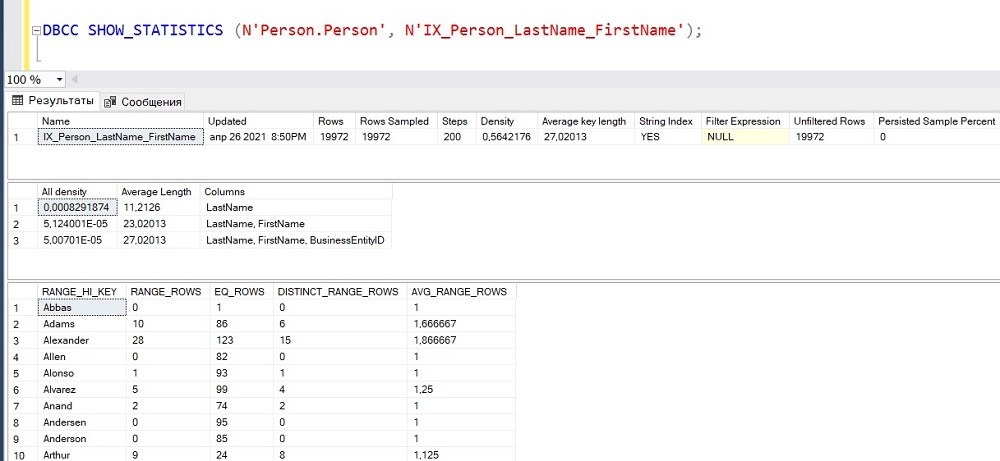
Информацию о статистике можно получить, например, с помощью команды DBCC SHOW_STATISTICS. В качестве параметра необходимо передать имя таблицы или индексированного представления, а также вторым параметром — имя индекса, статистики или столбца, для которого отображаются статистические данные.
В данном случае показан пример вывода информации о статистике некластеризованного индекса IX_Person_LastName_FirstName, который создан для столбцов LastName и FirstName таблицы Person в схеме Person.
Примечание! Более подробно работа со статистикой в Microsoft SQL Server будет рассмотрена в следующих статьях.
DBCC SHOW_STATISTICS (N'Person.Person', N'IX_Person_LastName_FirstName');
Параметры базы данных SQL Server, связанные со статистикой
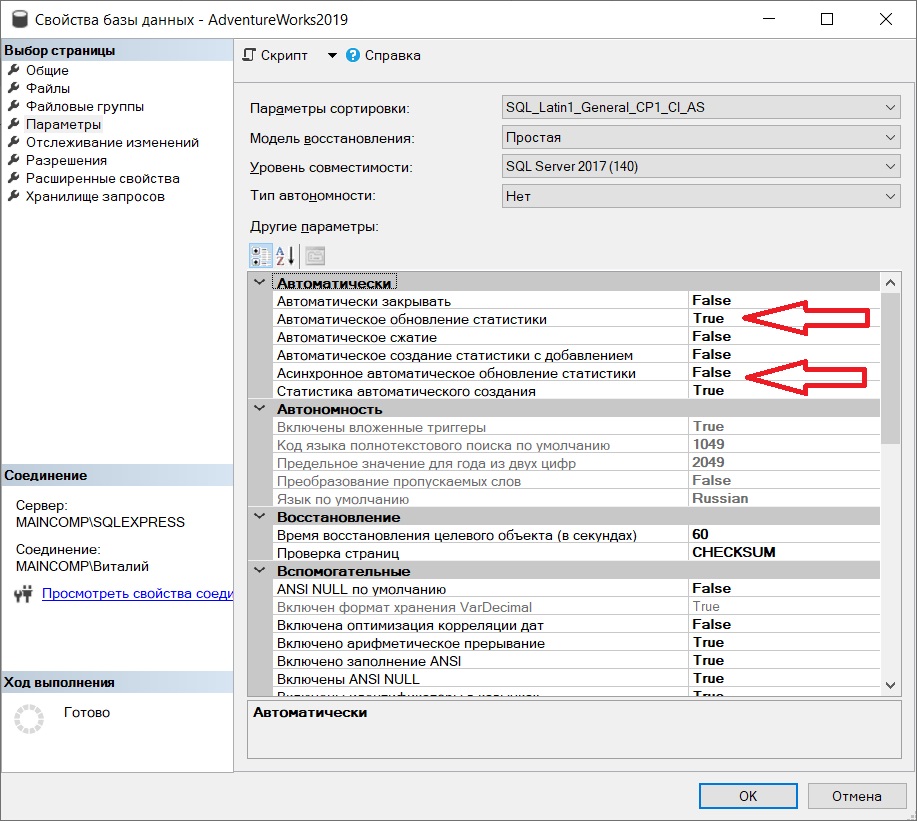
В Microsoft SQL Server предусмотрено три параметра, которые влияют на условия и методы создания и обновления статистики. Эти параметры задаются только на уровне базы данных.
Данные параметры можно изменять в интерфейсе SQL Server Management Studio в свойствах базы данных на вкладке «Параметры», а также с помощью стандартной инструкции ALTER DATABASE SET.
Заметка! Обзор функционала SQL Server Management Studio (SSMS).
Параметр AUTO_CREATE_STATISTICS
Данный параметр отвечает за автоматическое создание статистики, и если параметр включен, а он включен по умолчанию, то оптимизатор запросов при необходимости создает статистику по отдельным столбцам в предикате запроса, чтобы улучшить оценку кратности для плана запроса. Такая статистика по отдельным столбцам создается для столбцов, в которых отсутствует гистограмма в существующем объекте статистики.
Как было уже отмечено, параметр AUTO_CREATE_STATISTICS не определяет, создается ли статистика для индексов. Кроме того, этот параметр не создает отфильтрованную статистику. Он применяется строго к статистике по отдельным столбцам для всей таблицы.
Если оптимизатор запросов создает статистику при помощи параметра AUTO_CREATE_STATISTICS, имя статистики начинается с префикса _WA.
Параметр AUTO_UPDATE_STATISTICS
Данный параметр отвечает за автоматическое обновление статистики. Если параметр включен, а он по умолчанию включен, оптимизатор запросов определяет, устарела ли статистика, и при необходимости автоматически обновляет ее, если она используется в запросе.
Это действие также называется повторной компиляцией статистики. Статистика становится устаревшей после изменений данных в результате операций вставки, обновления, удаления или слияния.
Оптимизатор запросов определяет, когда статистика может оказаться устаревшей, подсчитывая операции модификации строк с момента последнего обновления статистики и сравнивая количество изменений строк с пороговым значением. Пороговое значение зависит от кардинальности таблицы, что можно определить как количество строк в таблице или индексированном представлении.
В общей практике принято считать, что пороговое значение, при котором SQL Server будет считать статистику устаревшей и обновит ее, это примерно 20% от количества строк в таблице, хотя алгоритм определения порогового значения, конечно же, чуть сложнее. Иными словами, SQL Server обновит статистику если в таблице изменилось примерно 20% данных. Например, если в таблице 100 000 строк, SQL Server обновит статистику если изменится 20 000 строк.
Начиная с 2016 версии алгоритм определения порогового значения был усовершенствован, и теперь может использовать понижаемое динамическое пороговое значение, которое изменяется в зависимости от кардинальности таблицы в момент оценки статистики. Благодаря этому изменению статистика для больших таблиц будет обновляться чаще. Дело в том, что до 2016 версии существовала проблема, когда у больших таблиц статистика обновлялась крайне редко, так как, например, если в таблице было скажем несколько миллиардов записей, то по этому алгоритму статистика должна обновится, когда изменятся сотни миллионов строк, что, как Вы понимаете, будет случаться крайне редко.
Заметка! Рейтинг популярности систем управления базами данных (СУБД).
Оптимизатор запросов проверяет наличие устаревшей статистики перед компиляцией запроса и до выполнения кэшированного плана запроса. Перед компиляцией запроса оптимизатор запросов с помощью столбцов, таблиц и индексированных представлений в предикате запроса определяет статистические данные, которые могли устареть. Перед выполнением кэшированного плана запроса компонент Database Engine проверяет, ссылается ли план запроса на актуальную статистику.
Параметр AUTO_UPDATE_STATISTICS применяется к объектам статистики, которые создаются для индексов, отдельных столбцов в предикатах запросов, и к статистике, создаваемой инструкцией CREATE STATISTICS. Этот параметр также применяется к отфильтрованной статистике.
Примечание! Выключать параметр AUTO_CREATE_STATISTICS и параметр AUTO_UPDATE_STATISTICS без веских на то оснований крайне не рекомендуется, т.е. это стоит делать осознанно.
Параметр AUTO_UPDATE_STATISTICS_ASYNC
Обновление статистики может выполняться синхронно или асинхронно. Данный параметр определяет, какой режим обновления статистики использует оптимизатор запросов: синхронный или асинхронный. По умолчанию параметр асинхронного обновления статистики отключен, соответственно, оптимизатор запросов обновляет статистику синхронно.
При синхронном обновлении статистики запросы всегда компилируются и выполняются с актуальной статистикой. Когда статистика устарела, оптимизатор запросов ожидает обновленную статистику перед компиляцией и выполнением запроса.
При асинхронном обновлении статистики запросы компилируются с существующей статистикой, даже если она устарела. Если статистика при компиляции запроса является устаревшей, оптимизатор запросов может выбрать неоптимальный план запроса. Как правило, статистика обновляется вскоре после этого. Запросы, которые компилируются после обновления статистики, будут использовать обновленную статистику.
В общих случаях рекомендуется использовать синхронную статистику, так как это позволяет гарантировать актуальность статистики.
Асинхронная статистика рекомендуется для достижения более прогнозируемого времени ответа на запросы, иными словами, этот параметр надо включать только в том случае, когда ваши запросы ждут синхронного обновления статистики слишком часто, и это вызывает проблемы производительности, например, в следующих случаях:
- Приложение часто выполняет один и тот же запрос, схожие запросы или схожие кэшированные планы запроса. Асинхронное обновление статистики может обеспечить более прогнозируемое время ответа на запрос по сравнению с синхронным, так как оптимизатор запросов может выполнять входящие запросы, не ожидая появления актуальной статистики. Это устраняет задержку в некоторых запросах, при этом не влияет на другие запросы.
- Если в приложении установлено небольшое время ожидания ответа от сервера баз данных, то возможны случаи, когда ожидание синхронной статистики может вызвать ошибку таймаута.
Обновление асинхронной статистики выполняется с помощью фонового процесса. Когда запрос готов к записи обновленной статистики в базу данных, он пытается получить блокировку изменения схемы для объекта метаданных статистики. Если другой сеанс уже удерживает блокировку того же объекта, обновление асинхронной статистики блокируется до тех пор, пока не появится возможность получить блокировку изменения схемы. Аналогичным образом сеансы, которым требуется получить блокировку схемы (Sch-S) для объекта метаданных статистики для компиляции запроса, могут блокироваться фоновым сеансом асинхронного обновления статистики, который уже удерживает блокировку модификации схемы или ожидает ее получение. Таким образом, для систем с очень частыми компиляциями запросов и частыми обновлениями статистики использование асинхронной статистики может повысить вероятность проблем с блокировками.
Параметр AUTO_UPDATE_STATISTICS_ASYNC применяется к объектам статистики, которые создаются для индексов, отдельных столбцов в предикатах запросов, и к статистике, создаваемой инструкцией CREATE STATISTICS.
Примечание! Статистика по локальным временным таблицам всегда обновляется синхронно независимо от параметра AUTO_UPDATE_STATISTICS_ASYNC. Статистика по глобальным временным таблицам обновляется синхронно или асинхронно в соответствии с параметром AUTO_UPDATE_STATISTICS_ASYNC, заданным для пользовательской базы данных.
Заметка! Курсы по Transact-SQL для начинающих.
На сегодня это все, надеюсь, материал был Вам полезен, пока!






