
Приветствую Вас на сайте Info-Comp.ru! Сегодня мы с Вами поговорим о том, как обновлять статистику в Microsoft SQL Server, при этом мы рассмотрим несколько способов обновления. Напомню, в предыдущих материалах мы говорили о том, как получать информацию о статистике, как ее создавать и удалять.

Для начала по традиции давайте вспомним, что же такое статистика в Microsoft SQL Server.
Статистика – это статистические сведения о распределении значений в одном или нескольких столбцах таблицы, и эти сведения использует оптимизатор запросов Microsoft SQL Server для создания планов выполнения запросов, в частности для оценки кратности, т.е. числа строк в результатах запроса. Такая оценка кратности позволяет оптимизатору запросов создать оптимальный план выполнения запроса.
Примечание! Более подробно о том, что такое статистика в Microsoft SQL Server, для чего она нужна и из чего состоит, мы говорили в отдельном материале – Статистика в Microsoft SQL Server, поэтому перед тем как продолжить чтение данной статьи, я рекомендую прочитать этот материал.
Обновление статистики
Вводная информация
Начать хотелось бы с того, что Microsoft SQL Server автоматически обновляет статистику, если включен параметр AUTO_UPDATE_STATISTICS. По умолчанию данный параметр включен, и таким образом, оптимизатор запросов автоматически определяет, устарела ли статистика, и при необходимости обновляет ее. Это действие также называется повторной компиляцией статистики.
Отсюда можно сделать вывод, что по умолчанию SQL Server автоматически обновляет статистику, и никаких дополнительных действий по обновлению статистики выполнять не требуется.
Однако, в некоторых случаях можно повысить производительность, выполняя обновление статистики чаще, чем это происходит по умолчанию. Это связано с тем, что триггером, т.е. событием, которое вызывает автоматическое обновление статистики, служит количество изменений данных в результате операций вставки, обновления, удаления или слияния, что на самом деле логично, т.е. если какое-то количество данных изменилось, то, соответственно, существующая статистика основана на устаревшем количестве данных и ее необходимо обновить.
Но все дело в том, что достижение порогового значения по количеству изменений, не всегда происходит быстро и в то время, когда нам нужно.
В общей практике принято считать, что пороговое значение, при котором SQL Server будет считать статистику устаревшей и обновит ее, это примерно 20% от количества строк в таблице, хотя алгоритм определения порогового значения, конечно же, чуть сложнее. Иными словами, SQL Server обновит статистику если в таблице изменилось примерно 20% данных. Например, если в таблице 100 000 строк, SQL Server обновит статистику если изменится 20 000 строк. Таким образом, может возникнуть ситуация, что Вы разово изменили достаточно большое количество данных, но это значение меньше порогового, и статистика, соответственно, автоматически не обновляется, и как следствие оптимизатор запросов может строить менее эффективные планы, по сравнению с планами, которые он мог бы построить, основываясь на актуальной статистике.
Заметка! Транзакции в T-SQL – основы для новичков с примерами.
А если говорить про большие таблицы, то здесь даже до 2016 версии существовала серьезная проблема, связанная с тем, что у больших таблиц статистика обновлялась крайне редко, а то и вовсе не обновлялась, так как, например, если в таблице было несколько миллиардов записей, то по этому алгоритму статистика должна обновится, когда изменятся сотни миллионов строк, что, как Вы понимаете, будет случаться крайне редко.
Но начиная с 2016 версии алгоритм определения порогового значения был усовершенствован, и теперь может использовать понижаемое динамическое пороговое значение, которое изменяется в зависимости от кардинальности таблицы в момент оценки статистики. Благодаря этому изменению статистика для больших таблиц обновляется чаще.
SQL Server проверяет наличие устаревшей статистики:
- Перед компиляцией запроса оптимизатор запросов с помощью столбцов, таблиц и индексированных представлений в предикате запроса определяет статистические данные, которые могли устареть;
- Перед выполнением кэшированного плана запроса компонент Database Engine проверяет, ссылается ли план запроса на актуальную статистику.
Таким образом, обновление статистики гарантирует, что запросы будут компилироваться с актуальной статистикой.
Однако обновление статистики вызывает перекомпиляцию запросов. Поэтому обновлять статистику слишком часто не рекомендуется, необходимо найти компромисс между выигрышем в производительности за счет усовершенствованных планов запросов и потерей времени на перекомпиляцию запросов.
Рекомендации по обновлению статистики
Обновление статистики рекомендуется в следующих ситуациях
- Запросы выполняются медленно, т.е. если время ответа на запросы велико или непрогнозируемо, то следует убедиться, что для запросов есть актуальная статистика, и только после этого продолжить диагностику;
- После операций обслуживания, которые изменяют распределение данных, таких как усечение таблицы или массовая вставка большого количества строк (в процентном отношении). Это может предотвратить задержки в обработке запросов, вызванные ожиданием автоматического обновления статистики. Такие операции, как перестроение и реорганизация индекса, не изменяют распределение данных, и поэтому после выполнения таких операций не нужно обновлять статистику. Но обязательно стоит отметить, что перестроение индекса вызывает обновление статистики, это является побочным эффектом повторного создания индекса. При этом в случае реорганизации индекса, статистика не обновляется;
- Выполняются операции вставки в ключевые столбцы, отсортированные по возрастанию или по убыванию. Для статистики по ключевым столбцам, отсортированным по возрастанию или убыванию (например, столбец IDENTITY или столбцы отметок реального времени), может понадобиться выполнять обновление чаще, чем это делает оптимизатор запросов. Операции вставки добавляют новые значения в столбцы, отсортированные по возрастанию или по убыванию. Число добавляемых строк может оказаться слишком маленьким и не вызвать обновление статистики. Если статистика не является актуальной и запросы выполняют выборку из недавно добавленных строк, то в текущей статистике не будет оценки количества элементов для этих новых значений. Это может привести к неправильной оценке количества элементов и замедлить выполнение запроса. Например, запрос, который выполняет выборку из дат самых последних заказов на продажу, будет иметь неправильную оценку количества элементов, если статистика не обновлена и не содержит оценки количества элементов для дат самых последних заказов на продажу.
Способы обновления статистики
Обновить статистику можно с помощью среды SQL Server Management Studio или с помощью инструкций языка Transact-SQL. При этом параметр AUTO_UPDATE_STATISTICS рекомендуется все равно оставлять включенным, чтобы оптимизатор запросов продолжал регулярно обновлять статистику.
Чтобы определить время последнего обновления статистики, можно использовать функции sys.dm_db_stats_properties или STATS_DATE. Примеры использования данных функций, а также другого функционала SQL Server для просмотра статистки, мы подробно рассматривали в статье – Работа со статистикой в Microsoft SQL Server. Часть 1 – Просмотр статистики.
UPDATE STATISTICS
UPDATE STATISTICS – инструкция языка T-SQL для обновления статистки.
Упрощенный синтаксис
UPDATE STATISTICS table_name [index_or_statistics_name]
[ WITH options ];
- table_name – имя таблицы или индексированного представления, содержащего статистический объект;
- index_or_statistics_name – имя индекса, для которого обновляется статистика, или имя обновляемой статистики. Если данный параметр не указан, то оптимизатор запросов обновляет всю статистику для таблицы или индексированного представления, это статистика, созданная инструкцией CREATE STATISTICS, и статистика по отдельным столбцам, созданная при включенном параметре AUTO_CREATE_STATISTICS, и статистика, созданная для индексов;
- WITH – ключевое слово для перечисления параметров. Если предполагается запуск инструкции без параметров, указание данного ключевого слова не требуется;
- options – параметры, с которыми будет обновляться статистика. Если параметры не указаны, то статистика будет обновлена со значениями параметров по умолчанию. Доступны следующие параметры:
- FULLSCAN – вычисляет статистику путем просмотра всех строк в таблице или индексированном представлении. FULLSCAN и SAMPLE 100 PERCENT имеют одинаковые результаты. FULLSCAN не может быть использован с параметром SAMPLE;
- SAMPLE number { PERCENT | ROWS } – указывает приблизительное процентное соотношение или число строк в таблице или индексированном представлении для оптимизатора запросов, которые используются при обновлении статистики. Аргумент number для параметра PERCENT может иметь значение от 0 до 100, а для параметра ROWS аргумент number может иметь значение от 0 до общего числа строк. Фактическое процентное соотношение или число строк, отбираемых оптимизатором запросов, может не совпадать с заданным значением. Например, оптимизатор запросов просматривает все строки на странице данных. Команда SAMPLE полезна в особых случаях, в которых план запроса на основе выборки по умолчанию не является оптимальным. В большинстве случаев нет необходимости использовать команду SAMPLE, так как оптимизатор запросов делает выборку и определяет размер статистически значимой выборки по умолчанию, что требуется для создания высококачественных планов запроса. Параметр SAMPLE нельзя использовать вместе с параметром FULLSCAN. Если не указана ни одна из команд SAMPLE или FULLSCAN, оптимизатор запросов использует выбранные данные и вычисляет размер выборки по умолчанию. Не рекомендуется указывать значения 0 PERCENT и 0 ROWS. Если для PERCENT или ROWS указано значение 0, объект статистики будет обновлен без статистических данных;
- RESAMPLE – обновить каждый объект статистики, используя последнее значение частоты выборки. Использование данного параметра может вызвать просмотр полной таблицы. Например, статистика для индексов использует для частоты выборки просмотр полной таблицы. Если не указан ни один из параметров выборки (SAMPLE, FULLSCAN, RESAMPLE), оптимизатор запросов выполняет выборку данных и вычисляет размер выборки по умолчанию;
- PERSIST_SAMPLE_PERCENT = { ON | OFF } – если установлено значение ON, статистика будет сохранять заданный процент выборки для последующих обновлений, где явно не указан процент выборки. Если установлено значение OFF, процент выборки будет сбрасываться на значение по умолчанию при последующих обновлениях, где явно не указан процент выборки. Значение по умолчанию – OFF;
- ON PARTITIONS partition_number [, …n] – задает принудительное повторное вычисление статистик конечного уровня, для секций, указанных в параметре partition_number, с последующим их объединением для создания глобальных статистик. Параметр WITH RESAMPLE обязателен, потому что статистики секции, построенные с различной частотой выборки, нельзя объединить;
- ALL | COLUMNS | INDEX – обновить всю существующую статистику, созданную по одному или нескольким столбцам, или статистику, созданную для индексов. Если не указан ни один параметр, инструкция UPDATE STATISTICS обновляет всю статистику для таблицы или индексированного представления;
- NORECOMPUTE – отключает параметр автоматического обновления статистики AUTO_UPDATE_STATISTICS для указанной статистики. Если указан этот параметр, оптимизатор запросов завершает текущее обновление статистики и отключает обновление в будущем. Чтобы возобновить действие параметра AUTO_UPDATE_STATISTICS, снова выполните инструкцию UPDATE STATISTICS без параметра NORECOMPUTE или выполните процедуру sp_autostats. Использование этого параметра может привести к созданию неоптимальных планов запросов. Без крайней необходимости не рекомендуется использовать этот параметр
- INCREMENTAL = { ON | OFF } – в случае значения ON статистики повторно создаются как статистики отдельно по секциям. При значении OFF дерево статистик удаляется и SQL Server повторно вычисляет статистики. Значение по умолчанию – OFF. Если статистики по секциям не поддерживаются, возвращается ошибка;
- MAXDOP = max_degree_of_parallelism – переопределяет параметр конфигурации max degree of parallelism на время выполнения операции со статистикой. MAXDOP можно использовать для ограничения числа процессоров, используемых при параллельном выполнении планов. Максимальное число процессоров – 64. По умолчанию 0, т.е. в зависимости от текущей рабочей нагрузки системы будет использоваться реальное или меньшее число процессоров. Значение 1 подавляет формирование параллельных планов.
Заметка! Чем отличаются функции от хранимых процедур в T-SQL.
Примеры обновления статистики инструкцией UPDATE STATISTICS
Обновление всей статистики для таблицы Person.Person
UPDATE STATISTICS Person.Person;
Обновление статистики EmailPromotion2 у таблицы Person.Person
UPDATE STATISTICS Person.Person (EmailPromotion2);
Обновление статистики EmailPromotion2 у таблицы Person.Person с просмотром всех строк таблицы
UPDATE STATISTICS Person.Person (EmailPromotion2)
WITH FULLSCAN;
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
sp_updatestats
sp_updatestats – системная хранимая процедура, которая вызывает инструкцию UPDATE STATISTICS для всех таблиц в текущей базе данных.
Процедура возвращает список таблиц с указанием статистик, которые были обновлены.
Данная процедура может принимать один параметр:
- @resample = ‘resample’ – указывает, что процедура будет использовать параметр RESAMPLE у инструкции UPDATE STATISTICS. Если данный параметр не указан, sp_updatestats обновляет статистику с использованием выборки по умолчанию. Значение параметра по умолчанию – NO.
Примечание! sp_updatestats обновляет статистику отключенных некластеризованных индексов и НЕ обновляет статистику отключенных кластеризованных индексов. Про основы индексов можно почитать в статье – Индексы в Microsoft SQL Server.
Пример обновления статистки процедурой sp_updatestats
EXEC sp_updatestats;
Графический интерфейс SQL Server Management Studio
Статистику также можно обновить с помощью среды SQL Server Management Studio. Для этого в обозревателе объектов щелкните правой кнопкой мыши по контейнеру «Базы данных -> Таблицы -> Имя таблицы -> Статистика -> Имя статистики» и выберите «Свойства».
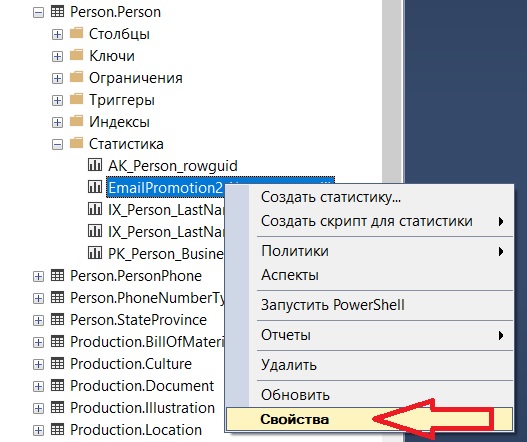
Заметка! Обзор функционала SQL Server Management Studio (SSMS).
В окне «Свойства статистики» необходимо поставить галочку «Обновить статистику для этих столбцов» и затем нажать кнопку ОК.
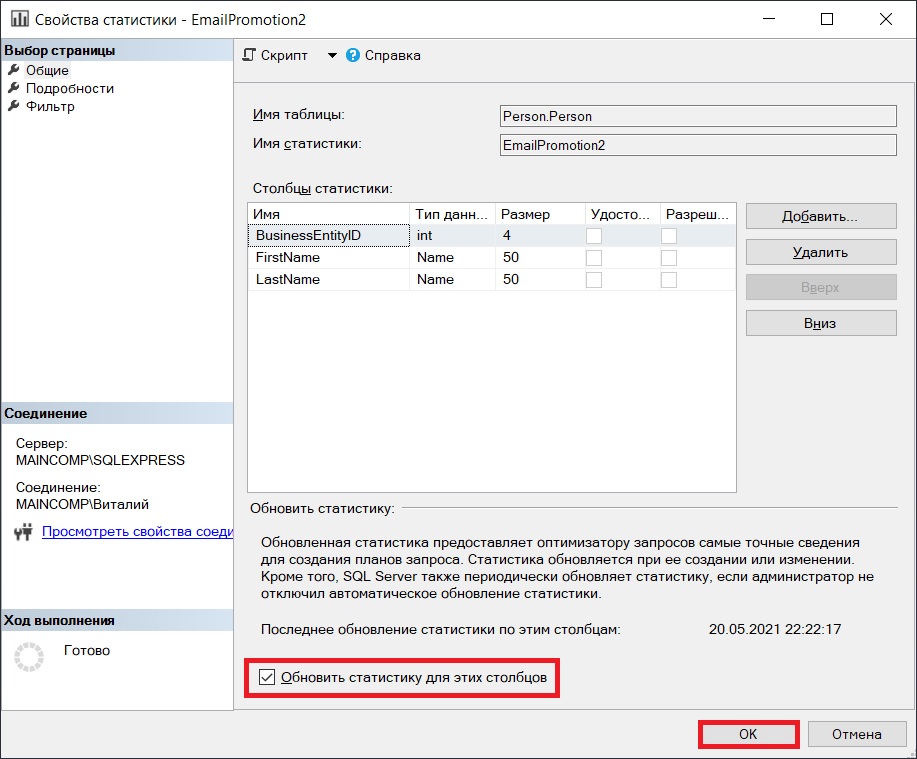
Заметка! Курсы по Transact-SQL для начинающих.
На сегодня это все, надеюсь, материал был Вам полезен и интересен. Удачи Вам, пока!






