
Приветствую всех посетителей сайта Info-Comp.ru! В данном материале мы с Вами рассмотрим процесс создания и удаления статистики в Microsoft SQL Server. Напомню, в предыдущем материале мы рассмотрели функционал SQL Server, который позволяет нам получать информацию о статистике.
Работа со статистикой в Microsoft SQL Server. Часть 1 – Просмотр статистики.

Итак, для начала давайте вспомним, что же такое статистика в Microsoft SQL Server.
Статистика – это статистические сведения о распределении значений в одном или нескольких столбцах таблицы, и эти сведения использует оптимизатор запросов Microsoft SQL Server для создания планов выполнения запросов, в частности для оценки кратности, т.е. числа строк в результатах запроса. Такая оценка кратности позволяет оптимизатору запросов создать оптимальный план выполнения запроса.
Примечание! Более подробно о том, что такое статистика в Microsoft SQL Server, для чего она нужна и из чего состоит, мы говорили в отдельном материале – Статистика в Microsoft SQL Server, поэтому перед тем как продолжить чтение данной статьи, я рекомендую прочитать этот материал.
Создание статистики
Сразу стоит отметить, что Microsoft SQL Server автоматически создает всю необходимую статистику, и никаких дополнительных ручных действий по созданию статистики выполнять не требуется.
Если говорить подробнее, то SQL Server автоматически создает статистику в двух случаях.
Первый — статистика автоматически создается для каждого индекса при его создании, такая статистика создается по ключевым столбцам индекса. Если индекс является отфильтрованным, SQL Server создает отфильтрованную статистику по подмножеству строк, которое указано для отфильтрованного индекса.
И второй — SQL Server автоматически создает статистику для отдельных столбцов, которые используются как аргументы поиска в предикатах запроса, однако в данном случае должен быть включён параметр базы данных AUTO_CREATE_STATISTICS (подробно параметры базы данных, которые влияют на статистику, мы рассматривали в материале – Статистика в Microsoft SQL Server). По умолчанию данный параметр включен, т.е. SQL Server настроен на автоматическое создание статистики. Однако стоит отметить, что он не влияет на создание статистики для индексов, т.е. даже если параметр AUTO_CREATE_STATISTICS выключен, статистика для индексов все равно будет создаваться.
В большинстве случаев такая автоматически созданная статистика обеспечивает создание высококачественного плана выполнения запроса.
Однако бывают случаи, когда план выполнения запроса можно улучшить, создав дополнительную статистику. Такая дополнительная статистика может фиксировать статистическую корреляцию, которую не учитывает оптимизатор запросов при создании статистики для индексов или отдельных столбцов. Приложение может иметь дополнительные статистические корреляции в данных таблицы. Если учитывать такие корреляции в объекте статистики, оптимизатор запросов сможет усовершенствовать планы запросов.
Например, план запроса можно улучшить путем использования отфильтрованной статистики по подмножеству строк данных или статистики по нескольким столбцам предиката запроса.
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
В каких случаях можно создавать статистику вручную
Создавать статистику вручную можно в следующих случаях:
- Предикат запроса содержит несколько коррелирующих столбцов, которые еще не включены в один индекс;
- Запрос выполняет выборку из подмножества данных;
- Для запроса отсутствует статистика;
- Помощник по настройке ядра СУБД рекомендует создание статистики.
Предикат запроса содержит несколько коррелирующих столбцов
Если предикат запроса содержит несколько столбцов, между которыми есть связи и зависимости, то статистика по нескольким столбцам может улучшить план запроса. Статистика по нескольким столбцам содержит статистику корреляции между столбцами, называемую плотностью, которая недоступна в статистике по отдельным столбцам. Плотность может повысить точность оценки количества элементов, если результаты запроса зависят от связей между данными из нескольких столбцов.
Если столбцы уже принадлежат одному индексу, то объект статистики по нескольким столбцам уже существует и его не нужно создавать вручную. Если столбцы не принадлежат одному индексу, можно создать статистику по нескольким столбцам, создав индекс по столбцам или вручную создать статистику инструкцией CREATE STATISTICS. Стоит отметить, что на поддержание индекса расходуется больше системных ресурсов по сравнению с объектом статистики. Если приложению не нужен индекс по нескольким столбцам, можно сэкономить системные ресурсы, создав объект статистики и не создавая индекс.
Заметка! Основы индексов в Microsoft SQL Server.
Запрос выполняет выборку из подмножества данных
Когда оптимизатор запросов создает статистику по отдельным столбцам и индексам, она создается по значениям во всех строках. Если запросы выполняют выборку из подмножества строк и в этом подмножестве присутствует уникальное распределение данных, то отфильтрованная статистика может улучшить планы запросов. Отфильтрованную статистику можно создать с помощью инструкции CREATE STATISTICS с предложением WHERE, в котором определить выражение предиката фильтра.
Для запроса отсутствует статистика
Если в результате ошибки или другого события оптимизатору запросов не удается создать статистику, он формирует план запроса, не используя статистику. SQL Server помечает статистику как отсутствующую и пытается восстановить ее перед следующим выполнением запроса.
Потерянная статистика отображается в виде предупреждения на графическом отображении плана выполнения запроса в среде SQL Server Management Studio.
В данном случае необходимо:
- Проверить, что включены параметры AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS;
- Проверить, что база данных доступна на запись, т.е. она не в состоянии «Только для чтения». Дело в том, что если база данных доступна только для чтения, новый объект статистики сохранить нельзя;
- Если предыдущие пункты выполнены, но статистика все равно не создается, можно создать статистику вручную с помощью инструкции CREATE STATISTICS.
Заметка! Чем отличается инструкция THROW от RAISERROR в T-SQL.
CREATE STATISTICS
CREATE STATISTICS – инструкция языка T-SQL для создания статистки вручную.
Упрощенный синтаксис
CREATE STATISTICS statistics_name
ON table_name ( columns )
[ WHERE filter_predicate ]
[ WITH options ];
где,
- statistics_name – имя создаваемой статистики;
- table_name – имя таблицы или индексированного представления, для которого требуется создать статистику. Если нужно создать статистику для другой базы данных, то требуется указывать полное имя таблицы;
- columns – один или несколько столбцов (каждый столбец указывается через запятую), которые будут включены в статистику. Столбцы должны быть указаны в порядке приоритета слева направо. Для создания гистограммы используется только первый столбец. Для статистики корреляции между столбцами, называемой плотностью, используются все столбцы;
- WHERE filter_predicate – условие для выбора подмножества включаемых строк при создании объекта статистики. Статистика, создаваемая с предикатом фильтра, называется отфильтрованной. Предикат фильтра использует простую логику сравнения и не может ссылаться на вычисляемый столбец, столбец определяемого пользователем типа, столбец типа пространственных данных или столбец типа hierarchyid. Сравнения с помощью литералов NULL с операторами сравнения недопустимы. Вместо этого используются операторы IS NULL и IS NOT NULL;
- WITH – ключевое слово для перечисления параметров. Если предполагается запуск инструкции без параметров, указание данного ключевого слова не требуется;
- options – параметры, с которыми будет создана статистика. Если параметры не указаны, то статистика будет создана со значениями параметров по умолчанию. Доступны следующие параметры:
- FULLSCAN – вычисляет статистику путем сканирования всех строк. FULLSCAN и SAMPLE 100 PERCENT имеют одинаковые результаты. FULLSCAN не может быть использован с параметром SAMPLE. Если не указать данный параметр, то по умолчанию SQL Server использует выборку для создания статистики и определяет размер выборки, необходимый для создания плана запроса высокого качества;
- SAMPLE number { PERCENT | ROWS } – указывает приблизительное процентное соотношение или число строк в таблице или индексированном представлении для оптимизатора запросов, которые используются при создании статистики. Аргумент number для параметра PERCENT может иметь значение от 0 до 100, а для параметра ROWS аргумент number может иметь значение от 0 до общего числа строк. Фактическое процентное соотношение или число строк, отбираемых оптимизатором запросов, может не совпадать с заданным значением. Например, оптимизатор запросов просматривает все строки на странице данных. Команда SAMPLE полезна в особых случаях, в которых план запроса на основе выборки по умолчанию не является оптимальным. В большинстве ситуаций нет необходимости указывать параметр SAMPLE, поскольку по умолчанию оптимизатор запросов применяет такие правила отбора, чтобы сформировать выборку статистически значимого размера, что необходимо для создания высококачественных планов запросов. Параметр SAMPLE нельзя использовать вместе с параметром FULLSCAN. Если не указана ни одна из команд SAMPLE или FULLSCAN, оптимизатор запросов вычисляет размер выборки по умолчанию. Не рекомендуется указывать значения 0 PERCENT и 0 ROWS. Если для PERCENT или ROWS указано значение 0, объект статистики будет создан без статистических данных;
- PERSIST_SAMPLE_PERCENT = { ON | OFF } – если установлено значение ON, статистика будет сохранять заданный процент выборки для последующих обновлений, где явно не указан процент выборки. Если установлено значение OFF, процент выборки будет сбрасываться на значение по умолчанию при последующих обновлениях, где явно не указан процент выборки. Значение по умолчанию – OFF;
- NORECOMPUTE – отключение автоматического обновления для создаваемой статистики. Использование этого параметра может привести к созданию неоптимальных планов запросов. Без крайней необходимости не рекомендуется использовать этот параметр;
- INCREMENTAL = { ON | OFF } – в случае значения ON статистика создается как статистика отдельно по секциям. При значении OFF статистика для всех секций комбинируется. Значение по умолчанию – OFF. Если статистики по секциям не поддерживаются, возвращается ошибка;
- MAXDOP – переопределяет параметр конфигурации max degree of parallelism на время выполнения операции со статистикой. MAXDOP можно использовать для ограничения числа процессоров, используемых при параллельном выполнении планов. Максимальное число процессоров – 64. По умолчанию 0, т.е. в зависимости от текущей рабочей нагрузки системы будет использоваться реальное или меньшее число процессоров.
Заметка! Транзакции в T-SQL – основы для новичков с примерами.
Пример создания статистики
В данном примере создается отфильтрованная статистика EmailPromotion2 по столбцам BusinessEntityID, FirstName, LastName для всех строк таблицы Person.Person, т.е. SQL Server просматривает все данные, которые содержит таблица (параметр FULLSCAN) и выбирает строки с EmailPromotion, равным 2 (WHERE EmailPromotion = 2).
CREATE STATISTICS EmailPromotion2 ON Person.Person (BusinessEntityID, FirstName, LastName)
WHERE EmailPromotion = 2
WITH FULLSCAN;
Если статистика создается по нескольким столбцам, как в нашем случае, то порядок столбцов в определении объекта статистики влияет на эффективность применения плотности для оценки количества элементов. Объект статистики хранит значения плотности для каждого префикса ключевых столбцов в определении объекта статистики.
В нашем случае объект статистики EmailPromotion2 содержит значения плотности для префиксов следующих столбцов:
- (BusinessEntityID)
- (BusinessEntityID, FirstName)
- (BusinessEntityID, FirstName, LastName)
Для (BusinessEntityID, LastName) плотность недоступна, т.е. если в запросе используются BusinessEntityID и LastName, но не используется FirstName, то плотность будет недоступна для оценки количества элементов.
sp_createstats
sp_createstats – системная хранимая процедура, которая вызывает инструкцию CREATE STATISTICS для создания статистики по отдельным столбцам для столбцов, которые еще не являются первым столбцом в объекте статистики.
Создание статистики по отдельным столбцам увеличивает число гистограмм, что может улучшить оценку количества элементов, улучшить планы запросов и как следствие производительность запросов. Первый столбец объекта статистики содержит гистограмму, а прочие – не содержат.
Процедура sp_createstats полезна для таких задач, как тестирование производительности, когда существенно важно время выполнения запросов и недопустимо ожидание построения статистики по отдельным столбцам оптимизатором запросов. В большинстве случаев нет необходимости использовать sp_createstats. Оптимизатор запросов создает статистику по одному столбцу, если это необходимо для улучшения планов запросов, если параметр AUTO_CREATE_STATISTICS имеет значение ON.
Синтаксис
sp_createstats @indexonly = 'indexonly' | 'NO'
, @fullscan = 'fullscan' | 'NO'
, @norecompute = 'norecompute' | 'NO'
, @incremental = 'incremental' | 'NO'
где,
- @indexonly – создает статистику только по столбцам, которые находятся в существующем индексе и не являются первым столбцом в определении индекса. Значение по умолчанию – NO;
- @fullscan – использует инструкцию CREATE STATISTICS с параметром FULLSCAN. Значение по умолчанию – NO;
- @norecompute – использует инструкцию CREATE STATISTICS с параметром NORECOMPUTE. Значение по умолчанию – NO;
- @incremental – использует инструкцию CREATE STATISTICS с параметром INCREMENTAL = ON. Значение по умолчанию – NO.
Пример создания статистики
EXEC sp_createstats @indexonly = 'indexonly',
@fullscan = 'fullscan';
В данном примере создается статистика по отдельным столбцам для всех подходящих столбцов, которые включены в индекс, но не являются первыми в индексе, при этом статистика вычисляется на основе всех строк.
Заметка! Чем отличаются функции от хранимых процедур в T-SQL.
Графический интерфейс SQL Server Management Studio
Кроме инструкций языка Transact-SQL создать статистику также можно и с помощью графического интерфейса SSMS. Для этого в обозревателе объектов щелкните правой кнопкой мыши по контейнеру «Базы данных -> Таблицы -> Имя таблицы -> Статистика» и выберите «Создать статистику».
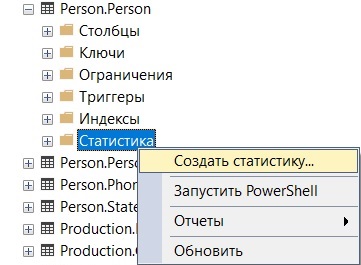
Далее на вкладе «Общие» необходимо ввести имя создаваемой статистики и добавить столбцы, по которым будет создана статистика, с помощью кнопки «Добавить».
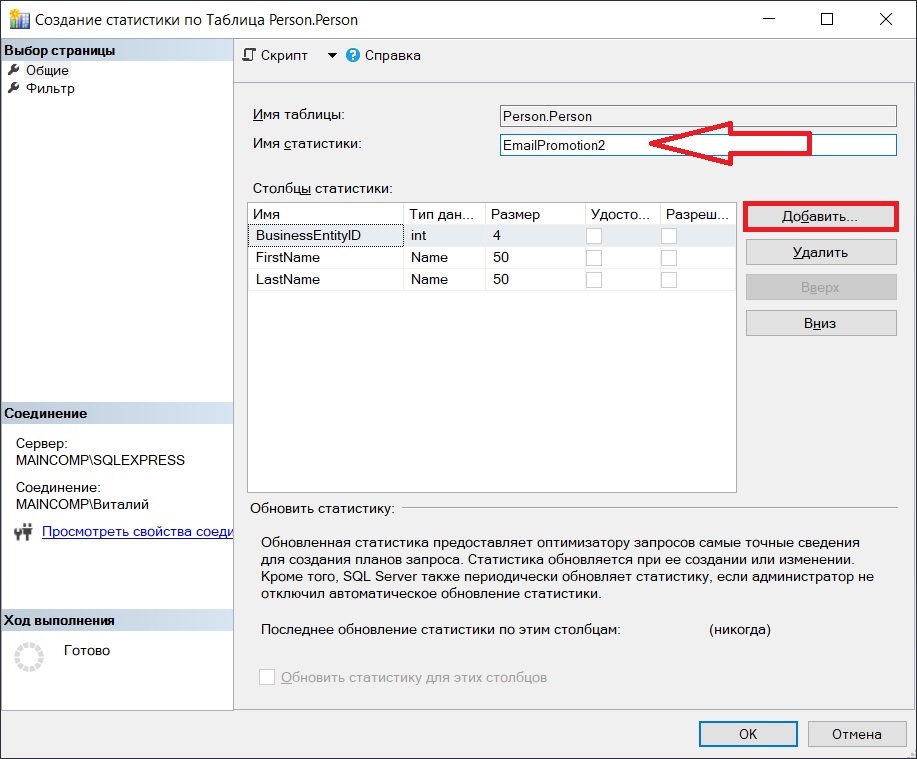
В принципе после этого можно сразу нажимать «ОК», однако, если Вы хотите создать отфильтрованную статистику, то на вкладке «Фильтр» можно добавить условие.
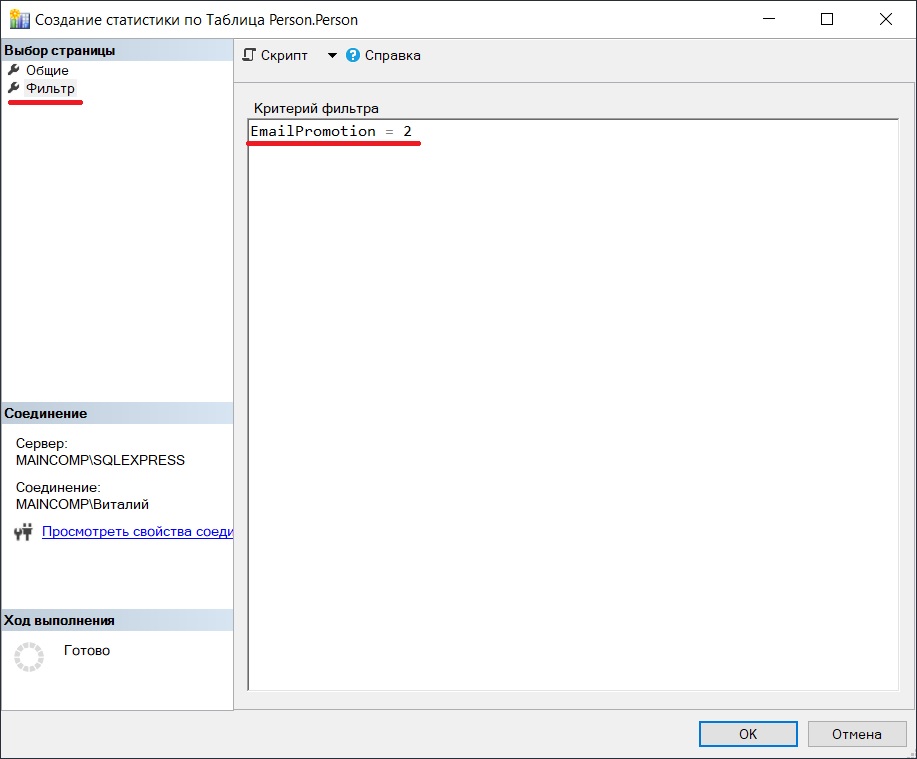
В данном случае мы создадим статистику, похожую на ту, которую мы создали с помощью инструкции CREATE STATISTICS.
Заметка! Обзор функционала SQL Server Management Studio (SSMS).
Удаление статистики
Удалить статистику в Microsoft SQL Server можно также несколькими способами.
DROP STATISTICS
DROP STATISTICS – инструкция языка T-SQL, которая удаляет статистику в Microsoft SQL Server.
Через запятую можно указать несколько объектов статистики.
В следующем примере удаляется объект статистки EmailPromotion2, который мы создавали для таблицы Person.Person.
DROP STATISTICS Person.Person.EmailPromotion2;
Графический интерфейс SQL Server Management Studio
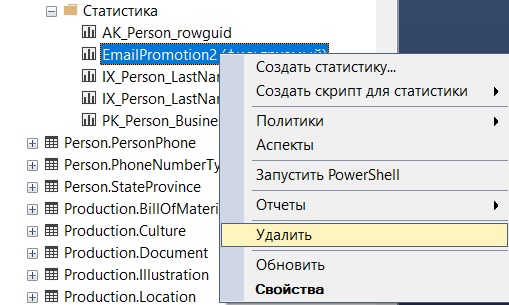
Удалить статистику можно также с помощью графического интерфейса SSMS.
Для этого необходимо щелкнуть правой кнопкой мыши по объекту статистики, который Вы хотите удалить, и выбрать «Удалить», в окне подтверждения нажать «ОК».
Заметка! Курсы по Transact-SQL для начинающих.
На сегодня это все, надеюсь, материал был Вам полезен и интересен, в следующих статьях мы поговорим о том, как обновлять статистику в Microsoft SQL Server.
Удачи Вам, пока!






