
Приветствую всех на сайте Info-Comp.ru! В этой небольшой заметке я покажу, как можно на SQL вывести повторяющиеся значения в столбце таблицы в Microsoft SQL Server. Все будет рассмотрено очень подробно и с примерами.

Заметка! Профессиональный видеокурс по T-SQL для начинающих.
Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
- Создание таблиц в Microsoft SQL Server (CREATE TABLE);
- Добавление данных в таблицы Microsoft SQL Server (INSERT INTO).
--Создание таблицы Goods
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_ProductId PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
GO
--Добавление строк в таблицу Goods
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 100),
('Монитор', 200),
('Сканер', 150),
('Принтер', 200),
('Клавиатура', 50),
('Смартфон', 300),
('Мышь', 20),
('Планшет', 300),
('Процессор', 200);
GO
--Выборка данных
SELECT ProductId, ProductName, Price
FROM Goods;
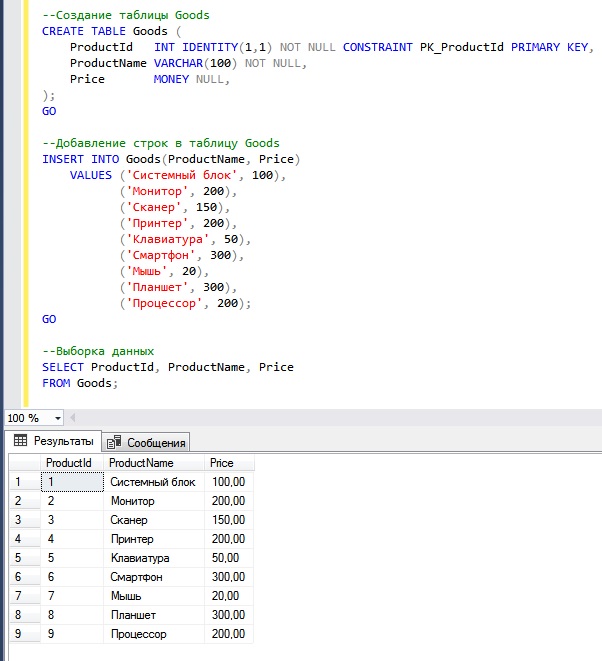
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Выводим повторяющиеся значения в столбце на T-SQL
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.
Вот пример всего вышесказанного.
--Определяем повторяющиеся значения в столбце SELECT Price, COUNT(*) AS CNT FROM Goods GROUP BY Price HAVING COUNT(*) > 1;
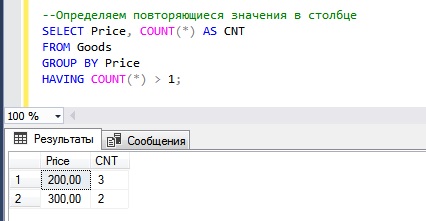
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
--Выводим все строки с повторяющимися значениями
WITH DuplicateValue AS (
SELECT Price, COUNT(*) AS CNT
FROM Goods
GROUP BY Price
HAVING COUNT(*) > 1
)
SELECT ProductId, ProductName, Price
FROM Goods
WHERE Price IN (SELECT Price FROM DuplicateValue)
ORDER BY Price, ProductId;
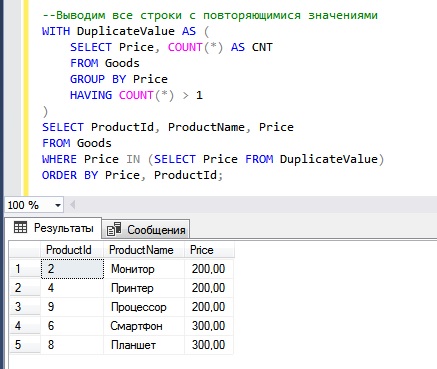
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги и пройти курсы:
- SQL код – самоучитель по языку SQL для начинающих;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода;
- Профессиональные видеокурсы по T-SQL.
У меня на этом все, надеюсь, материал был Вам полезен. Удачи Вам, пока!







Большое спасибо за статью!
Как оказывается элементарно на SQL это делается. Спасибо!
в моей таблице 650000 строк и 4 столбца: f1, f2, f3, files
бьюсь над задачей- как вывести все строки: где совпадают значения в столбце f2,
начинаются с одинакового символа в столбце f3,
и разные по значениям в столбце files.
подскажите, как переделать, я взял за основу вашу WITH DuplicateValue (..)
Спасибо большое, очень помогли!