
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о том, как происходит соединение таблиц в Microsoft SQL Server на физическом уровне, т.е. с помощью каких алгоритмов. В частности, мы рассмотрим такие типы соединения как: Nested Loops, Merge и Hash Match.

Введение
В языке T-SQL существуют следующие виды соединения таблиц:
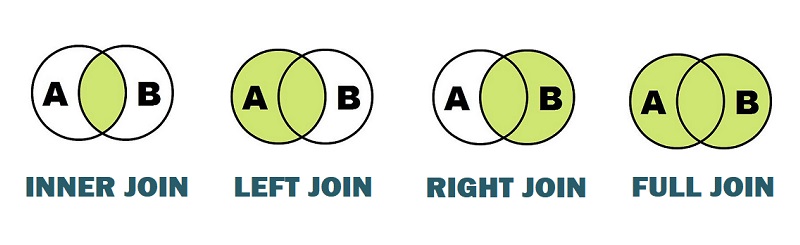
На физическом уровне в Microsoft SQL Server эти соединения реализуются с помощью специальных алгоритмов:
Какой из этих алгоритмов применить к тому или иному соединению, Microsoft SQL Server определяет в процессе построения плана выполнения запроса, так как в зависимости от условий каждый из этих алгоритмов может быть эффективнее остальных. Иными словами, в каких-то условиях эффективнее будет Nested Loops, а в каких-то Merge или Hash Match.
В плане выполнения запроса соединение таблиц обозначается с помощью следующих физических операторов, т.е. если Вы видите ту или иную иконку, значит, данные были соединены с помощью соответствующего алгоритма
|
Иконка |
Название оператора |
|
|
Nested Loops |
|
|
Merge Join |
|
|
Hash Match |
Какие еще существуют физические операторы и как они обозначаются в плане выполнения запроса, мы рассматривали в отдельной статье.
Заметка! Описание операторов плана выполнения запроса в Microsoft SQL Server.
Ну а сейчас давайте подробно рассмотрим каждый тип физического соединения таблиц в Microsoft SQL Server.
Типы физического соединения таблиц
Некоторые могут спросить: «А зачем нам вообще знать, как работает физическое соединение таблиц в Microsoft SQL Server?». Все дело в том, что если у Вас достаточно много задач, связанных с оптимизацией, то понимание внутренних процессов, понимание того, как работает тот или иной оператор в плане выполнения запроса, поможет Вам в случае необходимости скорректировать запрос и сделать его более эффективным.
Кроме этого, на собеседованиях на позиции, которые связаны с разработкой на T-SQL, очень часто любят спрашивать, как работает физическое соединение таблиц, иными словами, если Вы идете на позицию «T-SQL разработчик», то Вас, наверное, в 95% случаях спросят про физическое соединение таблиц Nested Loops, Merge и Hash Match.
Поэтому знание и понимание того, как фактически происходит соединение данных в Microsoft SQL Server, очень полезно.
Дополнительно рекомендую почитать про архитектуру обработки запросов в Microsoft SQL Server.
Заметка! Архитектура обработки SQL запросов в Microsoft SQL Server.
Nested Loops Join
Nested Loops – это оператор вложенных циклов, который отражает тип физического соединения данных.
Принцип работы Nested Loops следующий: SQL Server для каждого значения одного набора данных (обычно, где меньше записей), ищет соответствующее значение в другом наборе данных.
Иными словами, SQL Server берет первое значение из первой таблицы (она называется внешней) и сравнивает его последовательно со всеми значениями во второй таблице (она называется внутренней), если находит соответствие, то запись включается в итоговый набор данных. Когда значение из первого набора данных сравнилось со всеми знамениями из второго набора, то берётся второе значение первого набора и снова происходит сравнение со всеми значениями из второго набора и так происходит до тех пор, пока каждое значение из первой таблицы, т.е. внешней, не будет сравнено с каждым значением из второй таблицы, т.е. внутренней.
Таким образом, у нас два цикла, внешний и внутренний, отсюда и название – вложенные циклы.
В таком виде Nested Loops работает не очень эффективно, однако эффективность повышается, если данные внутренней таблицы отсортированы по соединяемому столбцу, например, если по нему создан индекс.
Заметка! Основы индексов в Microsoft SQL Server.
Таким образом, количество сравнений уменьшается за счет того, что значения отсортированы, а общая скорость работы повышается.
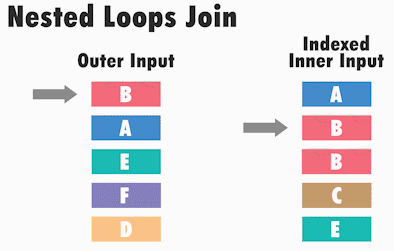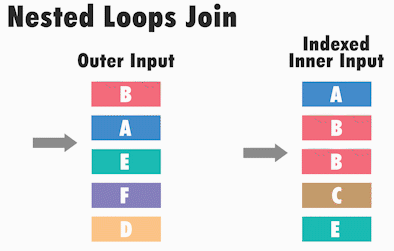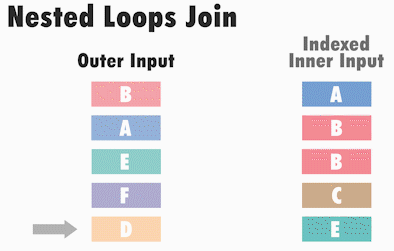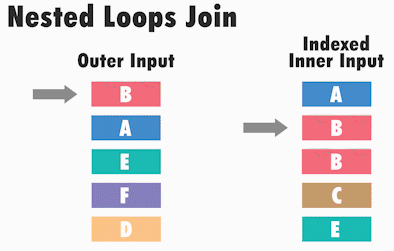
Тип физического соединения таблиц Nested Loops обычно возникает, когда мы соединяем наборы данных, где один из наборов имеет небольшой размер, а другой набор данных сравнительно большой и индексирован по соединяемым столбцам. Nested Loops встречается достаточно часто, так как является самой быстрой операцией соединения на небольшом объеме данных.
Примечание! Если два набора данных имеют достаточно большие размеры, то данный способ соединения будет крайне неэффективен.
Merge Join
Merge – соединение слиянием.
Данный тип физического соединения данных является самым быстрым, однако, он требует, чтобы оба набора данных были отсортированы, например, есть индексы по соединяемым столбцам.
Merge наиболее эффективен в тех случаях, когда два набора данных достаточно велики, и как уже было отмечено, отсортированы по соединяемым столбцам.
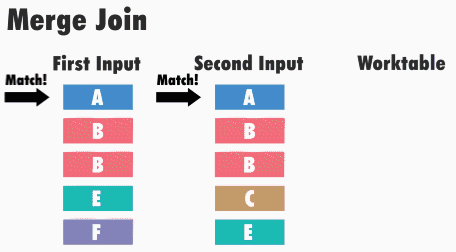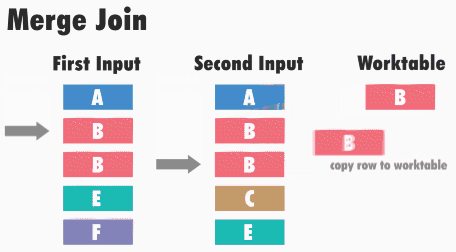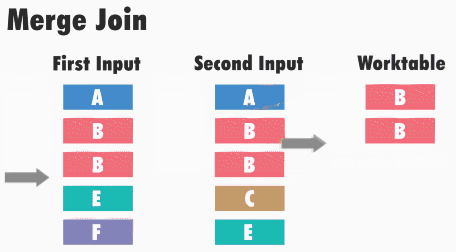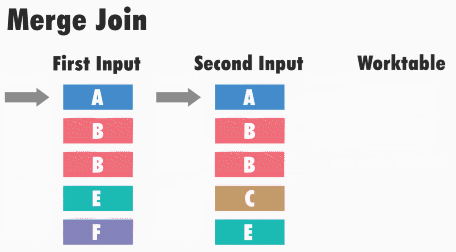
Принцип работы данного типа соединения следующий: SQL Server получает первые строки из каждого набора входных данных и сравнивает их. Затем он продолжает сравнение следующих строк из второго набора, до тех пор, пока значения соответствуют значению из первого набора данных. Как только значения больше не совпадают, SQL Server переходит к следующей строке в наборе с меньшим значением и продолжает выполнять сравнения.
Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется следующая строка и снова происходит сравнение. Этот процесс повторяется, пока не будет выполнена обработка всех строк, т.е. пока этот, назовем его, курсор, не дойдет до конца.
Данный алгоритм эффективен, потому что SQL Server не должен возвращаться и читать какие-либо строки несколько раз, т.е. чтение данных происходит только один раз.
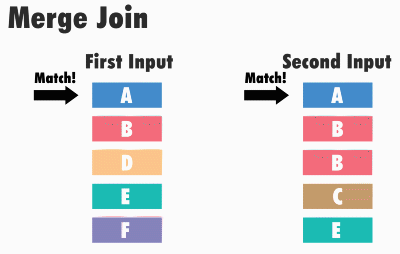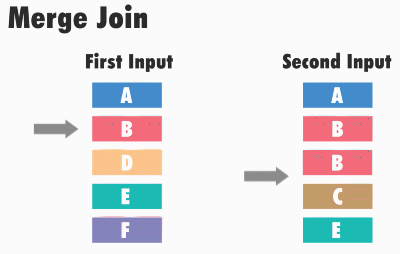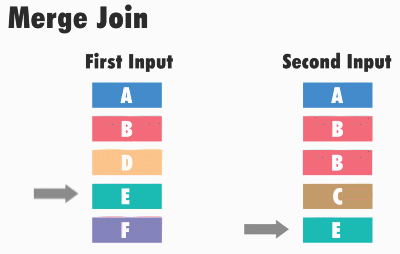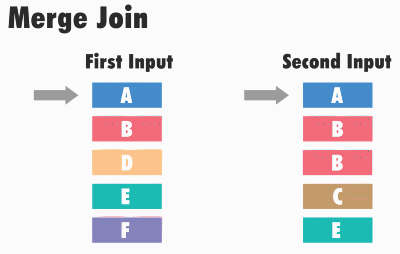
Однако алгоритм становится менее эффективен, когда в наборах существуют повторяющиеся значения, т.е. когда происходит соединение слиянием «многие ко многим».
В таких случаях SQL Server записывает любые повторяющиеся значения из второй таблицы во временную таблицу в базе данных tempdb и выполняет сравнения там. Затем, если эти значения также дублируются в первой таблице, SQL Server сравнивает их со значениями, которые уже сохранены во временной таблице.
Примечание! Если оба набора данных велики и имеют сходные размеры, но не отсортированы, то соединение слиянием с предварительной сортировкой и хэш-соединение (Hash Match) имеют примерно одинаковую производительность. Однако хэш-соединения часто выполняются быстрее, если наборы данных значительно отличаются по размеру.
Hash Match Join
Hash Match – хэш-соединение.
Алгоритм соединения включает 2 фазы:
- Build
- Probe
В первой фазе «Build» строится хэш-таблица при помощи вычисления хэш-значения для каждой строки одного набора данных (обычно меньшего из двух). Эти хэши вычисляются на основе ключей соединения входных данных и затем сохраняются вместе со строкой в хеш-таблице.
После построения хэш-таблицы SQL Server начинает фазу «Probe». На этом этапе он для каждой строки другого набора данных, с помощью той же хэш-функции, вычисляет хэш-значение и осуществляет поиск совпадений по хэш-таблице. Если он находит совпадение для этого хеша, то затем он проверяет, действительно ли совпадают ключи соединения между строкой в хеш-таблице и строкой из второй таблицы (ему необходимо выполнить эту проверку из-за потенциальных хеш-коллизий).
Стоит отметить, что иногда могут возникать ситуации, когда на этапе «Build» хеш-таблица не может быть сохранена полностью в памяти. В таких случаях SQL Server сохраняет некоторую часть данных в памяти, а остальную часть перенаправляет в tempdb.
Это происходит, когда объем данных превышает размер, который может храниться в памяти, или когда SQL Server предоставляет недостаточный объем памяти, необходимый для соединения Hash Match.
Способ физического соединения данных Hash Match возникает, когда мы обрабатываем большие, несортированные и неиндексированные наборы данных, при этом он делает это достаточно эффективно.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!






